
A field report from Workato’s AI Hub, San Francisco
Natala Menezes, VP of Marketing at Workato, opened the evening with a framing that stayed in the room long after she left the stage. Workato is positioning itself not as a workflow tool but as “the enterprise 🔧 agentic orchestration platform.” One executes workflows. The other allocates cognition. That distinction is where most enterprise failures are currently hiding. The three talks that followed made the case across three layers: architecture, evaluation, and absorption.
A show of hands revealed something honest: most attendees had built a conversational agent in the past 30 days. Far fewer had put one in production. The space between those two facts is where the evening lived.

Chris Miller: The Delegation Architecture
Chris Miller carries a rare credential in this space: AWS Machine Learning Hero, Staff AI Software Engineer at Workato, and someone who has shipped production workloads across 100+ production deployments before most organizations had a policy for what an agent even was. That depth showed in how he framed the evening’s first problem. Not “how do you build an agent” but “how do you build an agent that doesn’t collapse under its own context.”
The diagnosis was precise. Single agents impress in demos. They degrade in production because complex, long-running tasks drive context saturation, leading to degraded coherence and task fidelity. The architecture response is decomposition: multi-agent systems where each sub-agent holds a bounded task, a specialized tool set, and a manageable context window. Miller’s framing pushed past the performance argument. Decomposition is a design discipline. It requires knowing, prior to implementation at the level of task topology design, what any one agent should not be asked to carry.
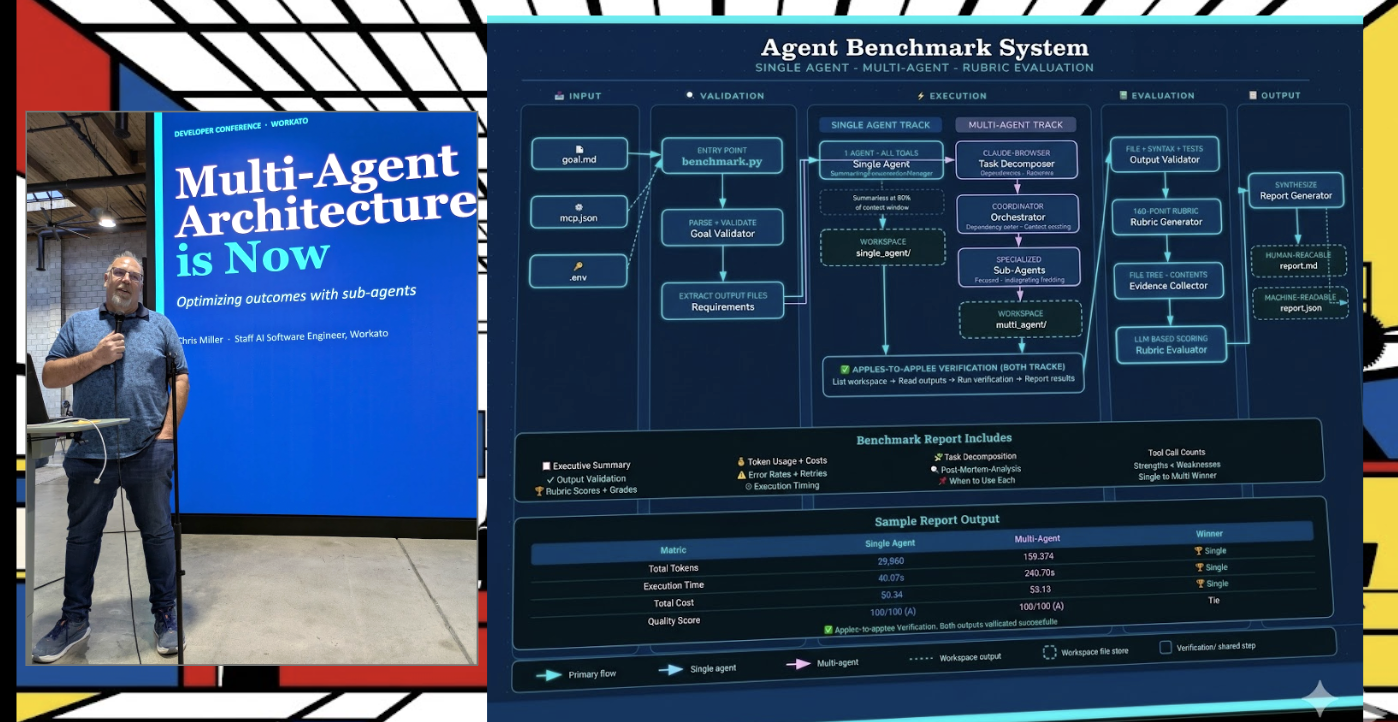
What followed was a walkthrough of task decomposition in practice: how to identify the boundaries of a real use case, assign specialized tools and skills to sub-agents, and measure the difference in token efficiency and output reliability. The pattern maps closely to how effective engineering teams are actually structured. No single engineer owns the full stack in a complex system. The orchestration layer decides who gets the task. Sub-agents execute within their domain. Output gets reconciled upstream. Multi-agent architecture is not a new metaphor. It is an old one, applied to systems that now reason.
The signal underneath the session is worth sitting with. Enterprise-grade agentic systems are no longer being built agent-by-agent. They are being designed as delegation architectures 🏗️ where the orchestration layer is as consequential as any individual capability. Organizations still treating agent deployment as a single-model problem are building for a world that already passed.

A question from the audience sharpened the architectural stakes considerably. Colleague Anish Mohammed asked whether the multi-agent system was implemented as a cyclic or acyclic graph, specifically a DAG. Chris acknowledged he had not implemented a full graph architecture in the current demo, crediting Anish for a more sophisticated framing than the session required. The exchange deserved the pause it created. A DAG enforces strict directionality: orchestrator to sub-agent, output flows forward, no revisiting. Clean tracing, deterministic evaluation, reproducibility, and tighter MLflow integration. A cyclic implementation opens the door to reflection loops where a sub-agent failure routes back to the orchestrator for re-evaluation and re-delegation. The cost is exactly what the evening’s 3rd speaker would document from Google’s own production experience: non-terminating retry loops with escalating token cost. The most production-hardened path, and a credible extension for the agentonomics-sample repository at github.com/workato-devs/agentonomics-sample, may be a hybrid: DAG by default with bounded, explicitly governed cycles at designated reflection nodes. Anish’s question didn’t just probe the demo. It pointed toward where the architecture needs to go.
Jules Damji: Paradigm Shift No One Warned Developers About
Jules Damji arrives at this conversation with unusual range. Co-author of Learning Spark 2nd Edition, O’Reilly instructor, & Staff Developer Advocate at Databricks where he has been embedded in the MLflow engineering team since 2016. That combination, advocacy fluency layered over distributed systems depth, is precisely what the agent quality problem needs right now. Someone who can name the paradigm shift & explain why most developers are not seeing it yet.
Jules Damji arrives at this conversation with unusual range. Co-author of Learning Spark 2nd Edition, O’Reilly instructor, and Staff Developer Advocate at Databricks where he has been embedded in the MLflow engineering team since 2016. That combination, advocacy fluency layered over distributed systems depth, is precisely what the agent quality problem needs right now. Someone who can name the paradigm shift and explain why most developers are not seeing it yet.

The shift Damji named at Workato’s AI Hub was not subtle. “The evaluation process is a paradigmatic shift,” he told the room. “Gen AI development is more eval-driven development, which is a slightly different paradigm.” For engineers trained in conventional software, this breaks established debugging mental models. In traditional development, a bug has a line number. In agentic systems, failure emerges from a probabilistic output space with no deterministic failure surface or reproducible trace. The agent sounded plausible and was wrong. Nothing in 40 years of software debugging culture prepares a team for that.
What replaces the old instinct is a structured loop Damji laid out with precision: prototype, trace, bring in subject matter experts, evaluate against rubrics, fix, validate, then repeat. “You don’t put it in production. You bring in a subject matter expert. You work with them. You identify issues, and then you go into that evaluate, fix, validate loop, till the LLM judges confirm the output aligns with the intended behavior.” The word “vibe-checking” surfaced more than once, not as endorsement but as diagnosis. Hours of subjective output review by developers who are not domain experts is not a quality methodology. It is a liability.
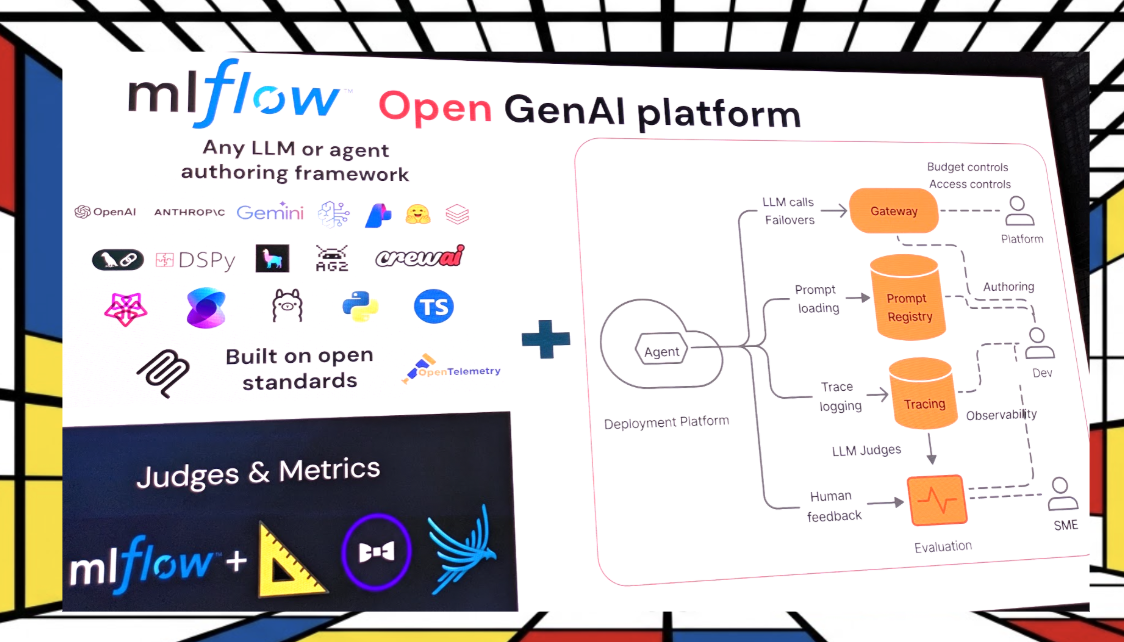
The instrument Damji demonstrated is MLflow 🔬, the open source platform originally designed for experiment lineage tracking and substantially rebuilt for GenAI and agent systems. mlflow.org is the entry point; the full codebase lives at github.com/mlflow/mlflow for developers who want to work directly with the platform. The four pillars he walked through, granular span tracing, LLM judge evaluation, prompt versioning, and AI governance, function together as an observability layer that makes the eval loop tractable at scale. The live demo used a multi-turn restaurant agent: four scenarios, coherence and search-necessity rubrics scored by LLM judges, all traced with token cost and latency surfaced per span. The point was not the restaurant. The point was that every step of the agent’s trajectory was visible, measurable, and improvable before anything touched production.
The sharpest moment in Q&A arrived when a developer pushed Jules on whether eval-driven prompt optimization was structurally analogous to gradient descent. Jules confirmed it without hesitation. The analogy holds with one critical difference: neural networks start from random weights. Prompt optimization starts from a defined baseline, a real sentence with real intent. The search space is narrower. But the mechanism is the same: adjust the input, measure the output against a target, reduce the error, repeat. Iterative error minimization against a defined objective function. 🔁 What the room was circling, and what Jules named directly, is that prompt engineering under evaluation pressure is not craft intuition. It is optimization under constraint. The mathematical lineage is real. For developers still treating prompts as creative writing rather than parameterized inputs to a loss function, that reframe changes how the work gets done.
What Damji’s talk added to the room’s understanding is the connection between tracing and trust. Developers cannot build confidence in a system they cannot see inside. The CAP theorem analogy he reached for, choosing between cost, latency, and quality at deployment, framed the tradeoff honestly. There is no configuration that optimizes all three. The evaluation harness does not eliminate the tradeoff. It makes the tradeoff legible, so the decision gets made deliberately rather than discovered in production at 2am.
The Problem Evaluation Cannot Solve
Benazir Fateh from Google arrived with a different kind of evidence. Her team deployed a resolution agent for Google’s technical writing org, a multi-agent system that triages documentation bugs, resolves the simple ones automatically, & routes the complex ones to human reviewers. Production-ready. Measurable. Adopted. Eventually.
What nearly stopped it had nothing to do with model quality. When the agent was assigned as the owner of incoming bugs, human reviewers disengaged. Review cycles lengthened. The fix was social architecture, not technical architecture: make the human the assignee, the agent the collaborator. Ownership signals responsibility. Responsibility drives review velocity.
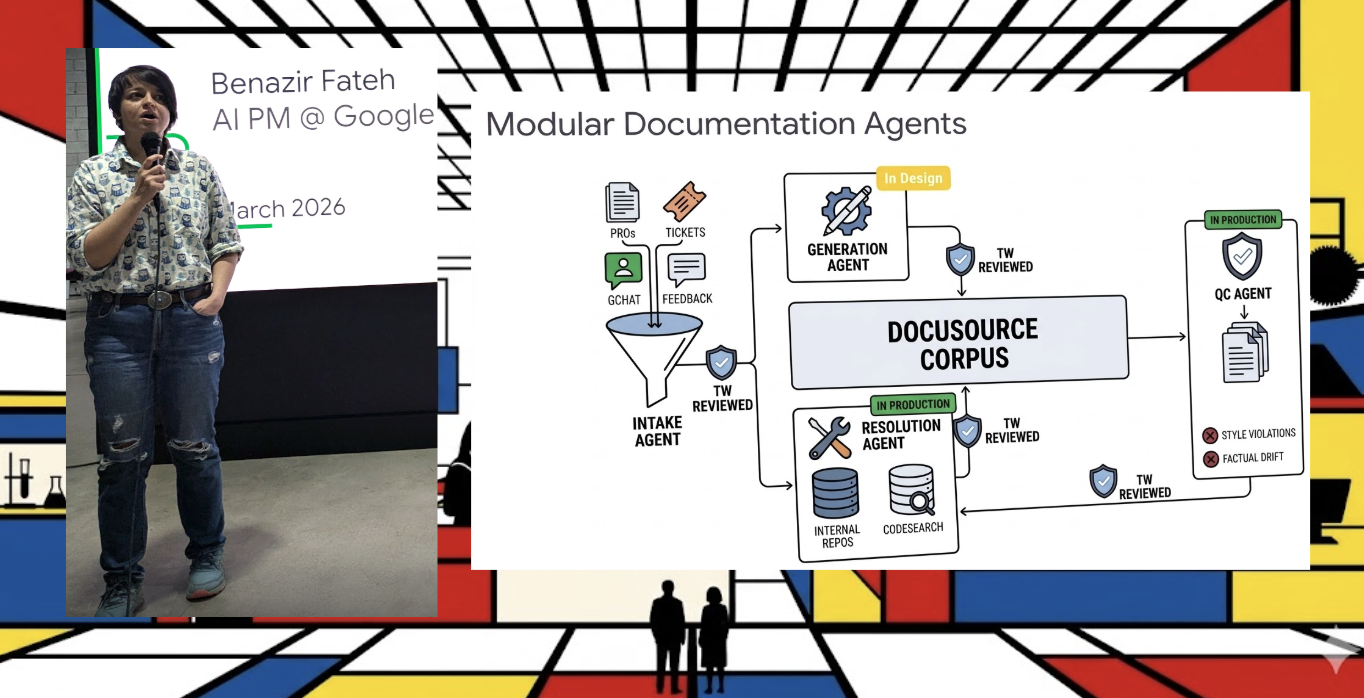
The playbook that emerged across Fateh’s seven patterns reads less like engineering documentation & more like change management theory. Reduce cognitive load. Map policies that restrict agent-authored code before building the agent. Teach users that working with agents is a skill, not an intuition. Put explicit failure acknowledgment into agent prompts so the system accepts defeat rather than loops forever.
The thesis she left hanging: organizations are not blocked by agent capability. They are blocked by absorption capacity. Knowing how to evaluate an agent’s output is not a skill most employees have been trained for. Trust has to be earned turn by turn, use case by use case.

The Discipline Gap
Two theses left the room in tension. One locates the constraint in task topology: know before a single line is written what each agent should not be asked to carry. One locates it in evaluation infrastructure: build the observability layer that tells developers, before production, whether an agent is trustworthy. The third, quieter than both, sits in human systems: even a trustworthy agent will fail adoption if the people around it don’t know how to work with it or feel displaced by it.
Neither thesis cancels the other. Both are true. & the teams that are actually putting agents into production, not just demos, appear to be the ones building for both simultaneously.
The question the evening didn’t answer, & probably couldn’t: at what point does an organization’s eval rigor become indistinguishable from its change management maturity?
That gap might be the real constraint on the next 18 months.
The Room as Signal
An edtech founder raised the question that tied the evening together without knowing it. She asked it plainly: how valuable is it to involve subject matter experts before the product ships, not just during evaluation, but during design?
Benazir’s answer was among the most honest of the night. The technical writing team at Google told her not to automate the writing. They loved the writing. Automate the triage, the prioritization, the administrative burden surrounding the work they actually wanted to do. The assumption that productivity gain comes from automating the most visible task is systematically wrong in early deployments. Visibility is not a proxy for friction. The SME knows where the friction actually lives. The developer usually guesses.
That exchange contained, in compressed form, the connective tissue between all three talks. Chris’s delegation architecture assumes someone has correctly bounded what each sub-agent should not do. Jules’s eval loop requires domain experts to label what good actually looks like. Benazir’s adoption playbook depends on understanding what humans want to protect before deciding what to hand to the agent. Architecture, evaluation, absorption: the same problem approached from three directions simultaneously.
The space that held this conversation earned its own note. Workato’s AI Hub in Dogpatch is one of San Francisco’s more architecturally considered event venues: exposed concrete block walls, warm Douglas fir ceiling beams, polished concrete floors, and a full-height glass wall that keeps the city present without letting it intrude. The room breathes. It was full. 🏛️ Natala Menezes set the tone from the first moments, genuinely at home in the space, framing Workato not as a vendor running an event but as a community investing in the conversation the industry needs to have. That framing was intentional ecosystem positioning, visible from the opening sentence.
Every question asked in a room like this is unfiltered practitioner intelligence. The DAG question. The gradient descent analogy. The SME timing debate. These are not survey responses. They are live traces of where developers are actually stuck, what frameworks are failing to address, and where the next adoption friction is forming. Organizations that capture, synthesize, and route that signal back into what they build next are running a feedback loop that no roadmap session replicates. The community events that do this well become something more than gatherings. They become the eval loop applied to the organization itself.
Workato built the room. Filled it. Asked the right speakers. The questions the audience left behind are still in the air. And somewhere in the platform, Dewy already knows what to do with it.
What gets built from them will separate demonstration from deployment.
PS. Deep thanks to Emily Fang & the entire Workato team for such high-level production – and to Asako Hayase & AICamp for bringing a community that asked the right questions.
