
Inside Web Discovery Summit 2025, Parag Agrawal explains why publisher relationships must rebuild from infrastructure up
Executive Summary: This article documents the afternoon panel from Bright Data’s Web Discovery Summit 2025 where infrastructure meets economics. While the keynotes (covered in “Half-Life Problem: Why Search Indices Became Archaeology”) diagnosed data decay making static search obsolete, Parag Agrawal Parallel Web Systems, Dhruv Batra Yutori, and Sarah Sachs Notion negotiated the harder question: how do you split a growing economic pie when publishers, platforms, and agents all claim different slices? The conversation revealed that search isn’t becoming commoditized at agent scale—it’s reopening as an unsolved infrastructure problem where compute replaces clicks as the primary quality signal, and trust boundaries (not technical limits) separate discovery from action.
Ferries cross the Bay at 15 knots. Agents cross the web at token speed. Yesterday at the Ferry Building’s SHACK15, overlooking the Port of San Francisco where physical cargo still moves on tides and schedules, Web Discovery Summit gathered builders designing infrastructure for a different port entirely: one where agents dock for synthesis, request access through protocol negotiation, and depart with compressed intelligence whose half-life approaches the speed at which markets reprice information.
The panel “Beyond Search: The Post-Human Web Experience” featured Parag Agrawal, founder and CEO of Parallel AI and former CEO of Twitter, alongside Dhruv Batra, chief scientist at Yutori (a startup building monitoring agents) and formerly senior director at Meta and professor at Georgia Tech. Sarah Sachs, AI lead at Notion (the collaborative workspace platform serving millions of knowledge workers), moderated what became less presentation than live negotiation over how platforms like hers should navigate a web suddenly optimized for patient machines rather than distracted humans.
Behavioral Divergence Creates Economic Inversions
Agrawal began by separating user impatience from agent endurance. “Humans on mobile devices are very impatient, learning what they want,” he opened. “If you put content below the fold, they don’t get there. Agents are not like that. They work on tokens. They’ll run 100 seconds because they’re working all night. So the problem is different. The business model is different.”
Batra reinforced the synthesis advantage agents hold over human browsers. “Somebody’s tracking discounts across forum threads with increasing complexity. For people, there’s so much noise: questions being asked, responses, more responses. Somewhere invisible, one person said the Android version of this is releasing in a few months, and in a different place somebody said the Windows version is releasing after that. A human had to consume all that, they probably wouldn’t be on top of it. For an agent, you can stitch it out and summarize it, and by the way here’s the release timeline, here’s the feature roadmap.”
This behavioral shift creates economic inversions traditional advertising models cannot accommodate. What replaces CPM? Cost per useful token extracted? Cost per workflow completed? “In some cases, the agent should pay for access to content,” Batra noted. “In some other cases, the agent should be paid for surfacing that information to the user, because you’re operating on a consumer or user’s expressed intent, and so that economic incentive can change. It’s going to take years for the web and the economic structures that were designed for human consumption to adapt for agents.”
The emerging mechanism might be called reciprocal monetization loops: agents both consume and create marketable attention, but attention measured differently. Not dwell time. Utility delivered.
Sachs pressed on the transition phase. “If I’m LinkedIn or Reddit, and I see now that a primary user of my data is agents, is it an adversarial relationship? Is it complementary?”
“It’s adversarial only because we haven’t yet figured out how to split the pie,” Agrawal responded. “It’s very obvious that with agents we can do more: people in finance, people in sales, people coding. By using agents, you can drive productivity. The economic pie, the pie grows. The problem is: how do you figure out a healthy way to split the pie so all participants are incentivized to collaborate? We’re in early phases of some of these partnerships now, working with publishers. We’re discovering along the way how to have all publishers who have very different business models (subscription-based, ad-based) want to collaborate with agents via us. As we work through more of these, this collaboration will only increase.”
Metrics Rebuild: From Clicks to Workflow Completion
Sachs, a former Google engineer, asked about quality signals in an agent-driven world. “When I was building search, you had your matrix: click-through rate, ad impressions. Every search quality review was super easy because if you regressed on any of those, it probably wasn’t being shipped. What does that look like today? What is the agent equivalent of an ad impression?”
Here Agrawal’s engineer’s logic surfaced: the elegance of compute as both signal cleaner and economic lever. “Those metrics, we use them. They’re extremely nice. But anytime you look at feedback and user signals, you have to understand that signal is noisy. Sometimes you can extract more signal if you have large numbers. Sometimes you can extract more signal by throwing away outliers.” He described Parallel’s architecture: “We consider 10,000 URLs based on ranking signals. Five to 30 percent of them eventually produce the answer. One to five percent get surfaced. Each of these is based on escalating levels of compute being thrown. Search ranking is just a body of ranking, followed by more compute, even more compute in the final abstraction.”
The key metric shift: “If a piece of content gets used by an agent and is useful for doing the work you set out to do, that’s more clear customer signal than a human clicking on a random block or URL. And we can use that signal to improve everything. You have an entirely scalable way of doing more compute to clean up the signal.”
Parallel positions itself not as a search engine but as a persistence layer: an agentic index that learns from time itself, from what agents actually use to complete work rather than what humans click momentarily.
Walled Gardens & Long-Running Scouts
Sachs raised the walled garden problem directly. “I can partner with LinkedIn directly and use the LinkedIn API. Or I can hire one of you to search LinkedIn for me with everything else and deal with the blending. How do I as a buyer choose which to buy?”
Agrawal was blunt. “Going into the strategies like Yahoo (you go to a directory, you pick your domain, then you search) I don’t think it works. If there are billions of these sources, going into one at a time doesn’t scale. You need someone with all that information processed, indexed, in order to allocate compute to find the one thing from 500 billion pages.”
Agrawal offered the self-driving car analogy. “Road networks were laid out for human driving. We’re having to share that space. We know we could make autonomous cars more efficient if we cordoned off the rest of humans and reset roads. But that’s not going to happen overnight. The web is kind of like that. We built it for human consumption and human servicing. For a long time, we’re going to have to share this space. There are 15,000 school districts in the US maintaining websites with some bespoke HTML developer that posts PDFs scanned from news articles. They don’t have APIs available for that information. You’re just going to have to share this space, and what that looks like from an AI perspective is machines acting like humans: clicking buttons, scrolling PDF pages, doing OCR on the fly. That’s what it’s going to look like for many years until it’s completed.”
On the access negotiation front, Batra noted the value exchange: “If someone doesn’t want you in their walled garden, you have to show them enough value. If there are enough requests coming to your service, if you were to open this up, it will drive traffic up, not down.”
Sachs asked about long-running agents, specifically Batra’s Scout product, which monitors the web continuously. “What does it look like when agents are spending weeks monitoring?”
Batra described Scout agents that have run for three months. “They’ve been going at some cadence (sometimes an hour, sometimes a day), gathering information, deciding whether to give an update to the human. An example: when Alex Wang was first hired back at OpenAI, I set a Scout up for any information posted about Alex Wang joining to build superintelligence. What came out over time: that team is now called Meta superintelligence, here are job postings, here’s a list of people who have just been hired, here are signs of tension inside Meta, here are departures. This is an extremely long-running query, so you have to deal with things like concept drift. We’re going to have agents running for days, weeks, months, years at a time.”
For educators and product leads alike, this shift demands teaching systems to learn longitudinally: evaluation metrics that reward comprehension accumulated over time, not recall measured in milliseconds.
Search Remains Unsolved at Agent Scale
Sachs challenged whether search would become commoditized. “In two years, will agent access to the web just be a given? Is search a commodity?”
Agrawal rejected the premise entirely. “You could have thought of search as a solved problem about a decade ago. It remains unsolved today. The amount of data on the web is extremely large and will continue to proliferate. It requires large amounts of compute to figure out what’s junk and what’s not, what matters. Every month, the bar will go up in terms of what should be possible and what is possible. As long as there’s no saturation point (being able to extract data, extract insights, take action) the problem will remain unsolved.”
He continued: “Agents in two years are not going to come and search on Parallel. Agents will tell Parallel when to call them and wake them up so they can do their work. Work that can be done today will get done today by these agents. What matters is what will happen tomorrow.”
Discovery vs Action: Parallel’s Line in the Sand
On whether Parallel would handle transactions (booking reservations, making purchases) Agrawal drew a clear boundary. “A lot of problems on the web feel like action but are actually discovery. You ask me: does this e-commerce site accept payment method X? By the logic of the question, there’s no action involved. But to process that question, you might have to take action: adding something to cart, going all the way to the end of a checkout flow to see if they allow it.”
He distinguished between exploratory and irreversible action. “At Parallel, our current line is: we leave the web as we found it. We don’t mutate things. If you want to get an OpenTable reservation, use us to figure out where you want the reservation. You spend 30 minutes as a human figuring that out, then click your way to make the reservation. Those authentication-layer tools: you really don’t want your login credentials alongside the wild, wild, wild west that is the web. You do want some separation of concerns. Even if we ship a product on the action side, it’s segmented. Search and discovery are infrastructure products. Action and changing the world are different.”
Sachs pushed back on latency. “What you just described feels like I’m doing it all over again. Your users are going to want more.”
Batra acknowledged the trust-building phase through Scout’s strategy. “You have to start with some value proposition that requires minimal trust. They’re not going to give you their logins or credit cards, but they are willing to see: can you take some cognitive load off the monitoring? Once something high-signal appears (‘Hey, that 6:30 PM reservation you’re looking for is available’), if you just say yes, we’ll actually go book it for you. Because the booking part was easy. Finding that it’s available is 90 percent of the way there.”
Notion’s Unsolved Problems
Toward the end, Agrawal turned the tables. “What do you need for Notion customers that no one is solving?”
Sachs answered immediately. “Walled gardens. That’s the content that’s the most painful for us today. Really loading and iterating on those web pages. And then the final question: can you do this for me? Can you reserve this? Can you make this action? We thought we fixed the problem by choosing processors that got us all this content. But then we have to use OpenTable API to make the reservation anyway. That’s the problem I don’t feel is solved. At the end of the day, LinkedIn and Twitter content is some of the richest content our customers want, not a random blog post where someone references the Twitter content, which is what’s surfaced at the top of the search today.”
She raised data exfiltration concerns. “When we have all of your enterprise content in that Notion workspace, we don’t want a third party to control whether information is being searched by your customers and then emailing Wired magazine that information. As an enterprise business that sells to other enterprises, we have to build for that.”
Her concern marked the dividing line between corporate governance and open discovery.
Batra offered a pragmatic view on the action layer. “If you can do something late at night, half asleep (like finding something on a website) agents will be able to do it very soon. This is a pure iteration problem. The gap is closing.”
Agrawal proposed an intriguing possibility. “If I told you I had an index of all actions you could take on the web, so you could search all buttons that allow you to make a reservation for a restaurant everywhere (maybe on OpenTable, maybe on Tock, maybe on Yelp, maybe somewhere else), would you want that index? Would you want to be able to search on the action space?”
Sachs responded enthusiastically. “Yes. And I actually would prefer that because I think data exfiltration is a huge risk that we pay very close attention to. But then we still have to actually take the action. And we have to build for that. And that’s kind of a solved problem. So, less concerning.”

What Comes Next
Standing outside Shack15 after the session, watching ferries cross the Bay, the conversation’s undertones felt more significant than its declarations. Agrawal spoke carefully about partnerships “in early phases,” about discovering collaboration models “along the way.” Batra described roads built for humans that machines must share. Sachs named the gaps (walled gardens, action completion, data control) that her team confronts daily.
Signals to Watch
Three mechanisms will define the next phase:
-
Emergence of agent-to-publisher licensing APIs. Automated negotiation protocols where agents request access terms machine-to-machine, bypassing human intermediaries entirely.
-
Standardization of long-context evaluation benchmarks. Quality metrics that reward synthesis across weeks of monitoring, not seconds of retrieval.
-
First public agent transaction frameworks. Protocol layers (ACP, AP2 equivalents) that separate discovery from execution while maintaining trust boundaries.
These signal the roadmap from infrastructure to monetization, from experimental partnerships to standardized economic exchange.
Six Months Out, One Year Forward
Six months from now, Parallel’s roadmap likely includes deeper publisher integrations, not just crawling but negotiated API access where economics align. The compute escalation Agrawal described (filtering 10,000 URLs down to the one percent that matter) suggests vertical integration into synthesis layers, not just retrieval. If agents spend weeks monitoring, they need memory architectures that compress context without losing signal. Concept drift isn’t a research problem anymore. It’s an operational one.
Technologically: expect autonomous protocol negotiation, where agents decide licensing terms without human involvement.
Behaviorally: human patience inversion. Users learning to wait for multi-day agent results that outperform instant search.
In a year, the agentic web probably looks less like APIs replacing browsers and more like hybrid protocols. Some content exposed through structured endpoints, most still requiring computer use to navigate human-built interfaces. Walled gardens don’t fall. They negotiate. The economic pie grows unevenly. Some publishers capture disproportionate value by controlling premium signal, others fade as agents route around low-quality sources. Discovery and action remain separated, not by technical limitation but by trust boundaries that take years to dissolve.
The conversation ended quickly, participants heading to flights and follow-up meetings. But the questions it surfaced (how to split growing pies, where to draw lines between exploration and transaction, which metrics actually signal agent satisfaction) won’t resolve in conference rooms. They’ll resolve in usage patterns, revenue splits, and infrastructure choices made by teams like Sachs’s, buying services from teams like Agrawal’s and Batra’s, all navigating a web that no longer waits for human attention to decide what matters.
Postscript
For those reading signals from this conversation, a few trajectories stand out. In six months, Parallel may extend beyond monitoring toward orchestration: agents that coordinate action across distributed systems, not just summarize change. Expect experimentation with persistent context windows, token-level quality signals, and negotiation protocols where agents request rather than retrieve.
Within a year, the agentic web could resemble an invisible operating layer beneath visible interfaces. Queries become continuous processes rather than discrete events. Discovery shifts from transaction to relationship. Interfaces blur into persistent behaviors that learn tempo, not just preference.
Worth questioning whether search remains the right frame, or if what emerges is something closer to a cognitive commons, where computation itself becomes the medium through which understanding forms and reforms, endlessly. In the next cycle, attention itself may cease to be the currency of the web, replaced by computational trust, measured not in clicks but in continuity.
Summit link
brightdata.com/lp/web-discovery-summit-oct-2025

Scouts in Yutori AI are user-defined, so queries vary by what each user sets up (e.g., tracking “agentic commerce” news, stealth companies from specific founders, or VC investments). Common examples from their team include monitoring portfolio updates, competitive startups, or partnerships.
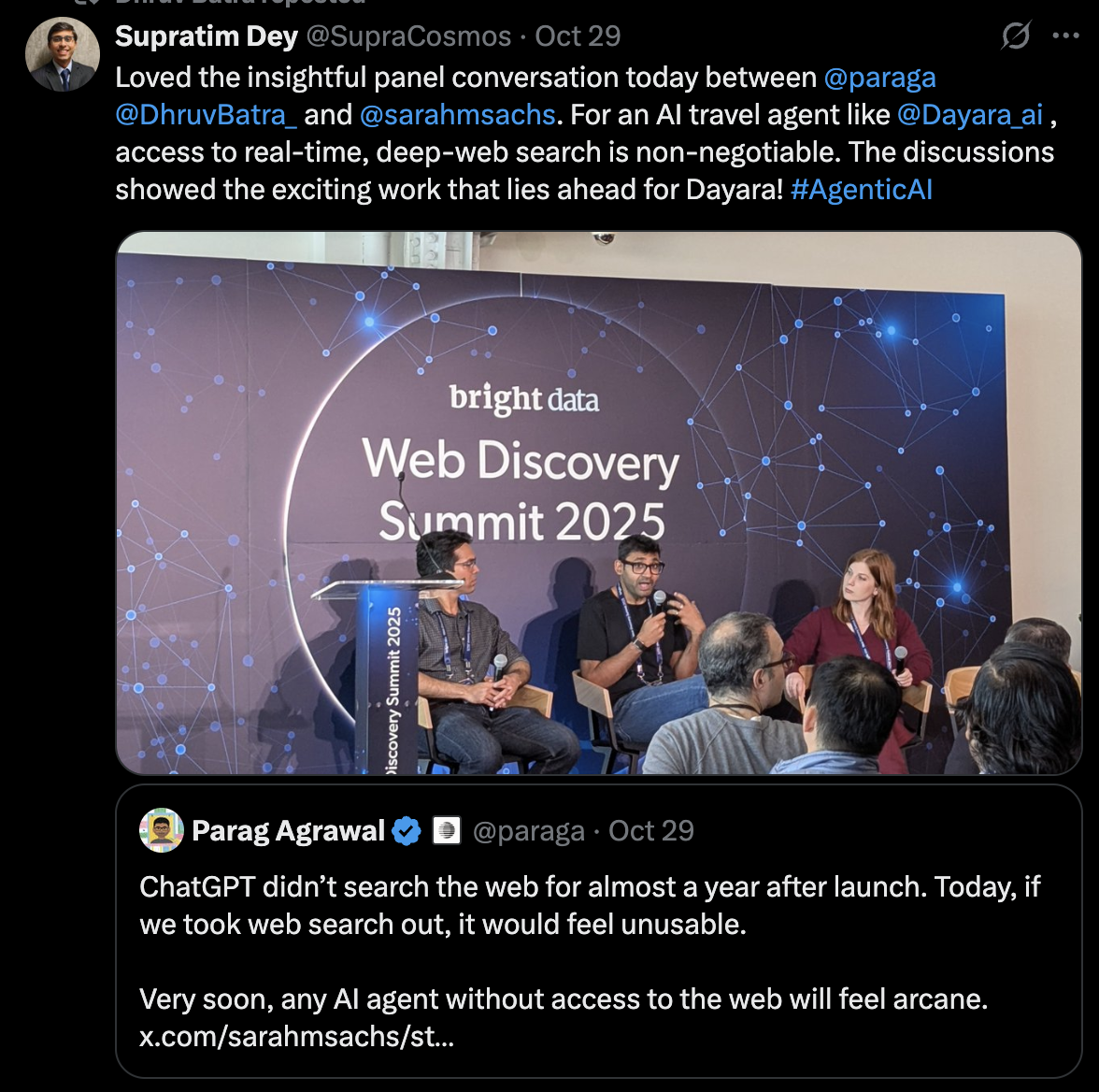
Dhruv: - x.com/DhruvBatra_/status/1979259540928630856