
Inside Web Discovery Summit 2025, Or Lenchner and Paddy Srinivasan reveal the temporal crisis forcing search architecture to rebuild from scratch
Executive Summary: Or Lenchner Bright Data and Paddy Srinivasan DigitalOcean delivered initial keynotes diagnosing why static search approaches collapse under data decay dynamics: social media content expires in hours, financial data in weeks, making snapshot-based indices archaeologically useless. Their infrastructure analysis set up the following panel moderated by Sarah Sachs (AI Lead, Notion) featuring Parag Agrawal (CEO, Parallel AI; former CEO, Twitter) and Dhruv Batra (Chief Scientist, Yutori; formerly Meta), who wrestled with the economic and trust negotiations these technical shifts demand, covered in tomorrow’s companion piece “Agent Economics: When Machines Become Primary Web Consumers.”
Search once organized knowledge. Now it curates ruins faster than they form.
If ports once moved coffee and timber, what moves through today’s infrastructure? At SHACK15, positioned above Port of San Francisco, Web Discovery Summit’s opening sessions yesterday examined the new cargo: knowledge with a half-life measured in hours. Or Lenchner, CEO of Bright Data, and Paddy Srinivasan, CEO of DigitalOcean, delivered back-to-back talks that together exposed why the antitrust remedy against Google, requiring a one-time data snapshot share, misunderstands what data actually is. Not a fixed asset. A decaying one.
The talks positioned what became the day’s central tension: infrastructure shifts happening faster than economic models can track. Search indices built for quarterly relevance now face minute-by-minute obsolescence. Agents need continuous access to live web states. Publishers must negotiate with machines that never sleep.

Google’s Data Gravity & the Antitrust Mirage
Lenchner opened by mapping Google’s data empire without romance. Email through Gmail. Documents via Drive. Images in Photos. Video on YouTube. E-commerce through Shopping. Local data from Maps. User behavior from Android devices. Expert knowledge from Scholar. IoT data through Home. The list continued, each vertical feeding what has become less a search engine than a real-time synthesis layer processing signals from billions of human activities daily.
Then came the antitrust context. Recent US court rulings require Google to share certain data with competitors. Specifically: the page rank algorithm, flagged user queries, click data. Technical scaffolding that took decades to build. But here’s the structural problem Lenchner identified: the remedy mandates sharing this data once, as a snapshot. No ongoing access. No temporal continuity.
“Sharing that only once as a snapshot is absolutely useless,” Lenchner stated flatly. He wasn’t making a legal argument. He was describing physics.
When Information Becomes Archaeology
Bright Data architected its analysis by combining external research with internal asset behavior, revealing data decay curves that make static snapshots futile. Social media content: half-life measured in hours. News: usable for days. Finance data: maybe a month. E-commerce: weeks at best. Real-time data for search indexing? Obsolete the moment it’s captured.
The graph Lenchner presented showed exponential decay across domains. A snapshot of social network data from six months ago isn’t just stale—it’s archaeologically useless for any application requiring current state. Even a week-old finance dataset becomes actively misleading, embedding outdated prices into models that assume relevance.
“You can’t build a search index from a snapshot that’s months old,” Lenchner explained. “The judge wasn’t wrong saying competitors must invest in their own infrastructure. Even with Google’s data shared once, you’d still need to collect continuously, in real time, to have anything functional.”
The half-life problem reframes competition entirely. Emergence suggests that advantage now measures continuity, not possession. Google’s moat isn’t the algorithm shared in the remedy. It’s the infrastructure that refreshes billions of data points every minute. Not the map. The sensing apparatus that redraws it constantly.
The Archive Nobody Can Use
Lenchner then shifted to Bright Data’s own infrastructure challenge. Eighteen months in, the company’s archive exceeds 400 billion web pages, growing by 3 million daily. It sounds like the foundation for a competitive search index.
But the half-life problem compounds here. “Having a copy of the internet is nice messaging,” Lenchner noted, “but for a search API or live index, it’s not always useful.” Training large language models? Archive data works. Building agent-accessible discovery systems? You need pages as they exist now, not as they existed when archived.
Bright Data is architecting toward continuity rather than custody. The pivot: from archival to continuous crawling, from static snapshots to API-accessible live data. The investment acknowledges what the antitrust remedy doesn’t – that search topology isn’t a possession but a process, less library than living tissue that must regenerate to stay viable.
Lenchner closed with a reframing that would echo through later panels: “The internet we’ve been using for 25 years - HTML pages humans browse - is becoming the infrastructure layer for the future internet. What we’re building is the connecting layer between that old internet holding actual data and this new emerging internet where agents operate. You don’t have AI without us.”
Not search replacing search. Infrastructure supporting synthesis. The old web as substrate, not destination.
Latency as Business Model
Paddy Srinivasan, DigitalOcean’s CEO, picked up the thread through a different lens: what happens when data decay meets generation shift in collective attention span. “We are having a generation shift in terms of our collective attention span,” he opened. “Social media decay happens in minutes. Even for other assets, it’s a handful of days before data becomes irrelevant.”
This creates what he termed “the data half-life crisis” - two forces converging. First, humans have become exceptionally efficient at generating data exhaust, doubling global data volume every 2.5 years. Second, relevance windows have collapsed. The combination means traditional approaches (static web searches, human-curated indices) can’t keep pace.
Regulators still legislate in quarters. Algorithms arbitrate in milliseconds. Courts imagine data as fixed asset. Infrastructure teams experience it as decay curve.
Srinivasan’s proposition: move data relevance decisions out of human hands, into agent architectures. But data relevance has two requirements that traditional search struggles with: freshness and speed delivered at global scale. “When you have fresh, relevant data delivered at very low latency, you gain relevancy,” he explained. “You can start changing the paradigm from frozen search indexes into a new world embedding live data into applications powered by AI.”
The shift isn’t search engines getting better. It’s search getting embedded into every application, democratizing what was centralized in a few dominant platforms. Not one omniscient index everyone queries. Millions of specialized engines, each focused on specific workflows, each requiring live data feeds that update continuously.
Building a Travel Agent in 24 Hours
Srinivasan demonstrated the concept through travel data, one of the most complex domains from a decay perspective. Flight status changes minute by minute. Accommodation pricing shifts hourly. Availability updates in real time. Yet most travel systems run on decades-old mainframe technology without public APIs.
His team built a working demo in 24 hours: an agent that understands natural language travel requests, pulls real-time flight and hotel data through Bright Data’s API, cross-references user calendar and preferences, formulates options, handles booking modifications, and adapts to price changes dynamically. The agent doesn’t rely on airline APIs that may not exist. It accesses data semantically, requesting what it needs and receiving structured responses.
The architecture: a DigitalOcean serverless function calling Bright Data’s API, returning structured flight information (times, costs, airlines, travel duration). Python code wrapped in natural language processing, with an agent builder configuring behavior parameters. No static knowledge base uploaded. The internet becomes the knowledge base, queried live as needed.
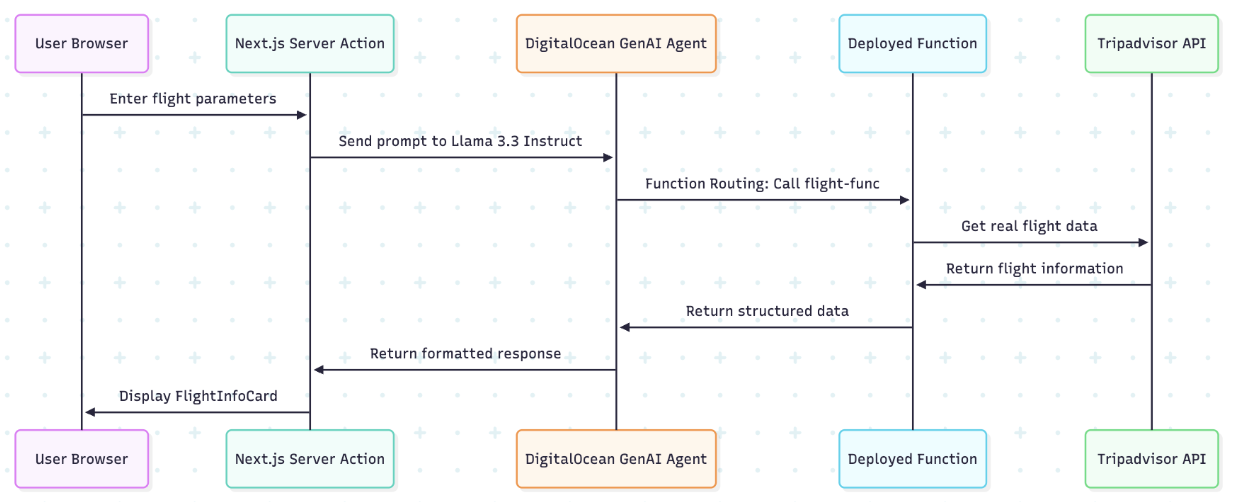
Srinivasan showed the agent in action. User requests a New York trip November 15–19. Agent knows departure city from user profile. Asks clarifying questions based on general knowledge about travel requirements. Checks available flights and hotels. Consults user’s calendar. Formulates travel plan. Recognizes a meeting scheduled for return day, suggests flying back the 18th instead. Selects different airports for optimal timing. Books preferred hotel chain. Requests confirmation specifying which credit card. After user adjusts hotel preference, agent modifies booking.
“By plugging this directly into the agentic platform, we gave it real-time connection to the world,” Srinivasan explained. “It can react to price changes, find last-minute deals, navigate complexity without relying on other organizations’ ability to provide API access.”
The demo wasn’t about replacing Expedia. It revealed something more fundamental: search once priced pages by popularity; agents will price them by utility per second. Not how many people click. How well information completes a specific workflow. This shifts data from commodity to situational awareness—valued not for permanence but for its ability to resolve uncertainty right now.
The demo operated at agent tempo rather than human browsing speed. Not interfaces designed for distracted mobile users. Protocols designed for patient machines that work through complexity systematically.

Centralization Stress Without Collapse
The contrast between these talks revealed competitive dynamics more nuanced than monopoly dissolution narratives suggest. Google maintains infrastructure advantages—continuous data collection across verticals, synthesis capabilities honed over decades, compute resources competitors can’t match. The antitrust remedy doesn’t eliminate these advantages. It barely touches them.
Worth considering whether causality runs backward: it isn’t that search indices became stale because of AI. AI emerged because our indices were already stale. The web accelerated past what centralized platforms could keep fresh. Agents appeared as solution to a latency problem human-speed updates couldn’t solve.
New entrants exploit specific gaps Google’s general-purpose architecture creates. Bright Data focuses on crawling infrastructure and API access, solving data freshness problems for companies that can’t build Google-scale collection systems. DigitalOcean provides the compute substrate where specialized agents run, democratizing what was previously platform-exclusive capability.
Google’s moat remains, but what it protects shifts. Raw indexing becomes less defensible as companies like Bright Data commoditize continuous web access. The emerging moat: synthesis layers that transform live data streams into actionable intelligence. Not who can collect data, but who can make sense of it fast enough to matter.
This creates a multi-layered ecosystem rather than winner-take-all dynamics. Google retains dominance in general search while specialized players carve out domains where freshness requirements exceed what centralized infrastructure can deliver economically. Travel booking. Financial monitoring. Supply chain tracking. Domains where minute-by-minute accuracy matters more than comprehensive coverage.
The Persistence Layer Nobody’s Built
Srinivasan closed with a provocation about data relevance mechanics. “If a piece of content gets used by an agent and is useful for doing the work you set out to do, that’s clearer customer signal than a human clicking on a random link. We can use that signal to improve everything. You have an entirely scalable way of doing more compute to clean up the signal.”
The half-life problem isn’t just data decay – it’s economic decay. Traditional signals (click-through rate, dwell time, ad impressions) measure attention, not utility. Agent-era signals must measure workflow completion, synthesis accuracy, task resolution. Not what people click momentarily but what agents actually use to finish work.
This suggests feedback architectures becoming the new competitive substrate. Search indices need to become persistence layers that learn from agent behavior over time. Not snapshots refreshed periodically. Living tissue that tracks which content proves useful across thousands of agent workflows, which sources provide signal versus noise, which data points remain relevant as contexts shift.
Srinivasan’s travel demo exemplified this: the agent didn’t just retrieve flight data, it learned which information mattered for decision-making (calendar conflicts, airport preferences, pricing thresholds). Each interaction refined what qualified as “useful.” Scale that across millions of workflows, and indices stop organizing pages. They start organizing utility.
Nobody’s built this yet. Google’s infrastructure still optimizes for human browsing patterns. Startups like those Srinivasan and Lenchner lead are assembling pieces—continuous crawling, API access, agent-native interfaces—but the full synthesis layer remains emergent.
Infrastructure Questions Becoming Economic Ones
Standing outside Shack15 between sessions, watching afternoon light angle across the Bay, the temporal crisis these talks exposed felt less technical than foundational. Data decay makes static approaches obsolete. Agent workflows require continuous access. Search indices need to learn from usage patterns, not just index content.
But infrastructure capability doesn’t determine adoption. Economics does. Questions surface:
If agents run continuously, who pays for the compute? If data relevance depends on freshness measured in minutes, how do publishers monetize access that never stops? When attention itself stops being the currency that matters, what replaces it? If the economic pie grows through agent-driven productivity gains, how do participants split it when traditional advertising models (impressions, clicks, dwell time) no longer capture value creation?
These infrastructure dynamics set up the negotiations that dominated the afternoon panel. When Parag Agrawal, Dhruv Batra & Sarah Sachs sat down to discuss “Beyond Search: The Post-Human Web Experience,” they weren’t debating theoretical futures. They were wrestling with immediate operational realities: how to build trust between agents and publishers, where to draw boundaries between discovery and transaction, which metrics actually signal that agents are doing useful work.
Lenchner and Srinivasan showed why the web’s substrate must rebuild. The panel that followed grappled with how to operate while that reconstruction happens—sharing roads built for humans with machines that never tire, negotiating access to walled gardens when APIs don’t exist, measuring quality when attention itself stops being the currency that matters.
Signals to Watch
Three mechanisms will define whether this infrastructure transition accelerates or fragments:
Standardized freshness protocols. APIs that specify decay curves by content type, allowing agents to decide which sources need continuous monitoring versus periodic refresh. Not all data spoils at social media speed. Differential freshness lets infrastructure scale economically. Watch for: public specifications from major platforms defining expected update frequencies by data type.
Agent-native quality metrics. Evaluation frameworks that reward synthesis across extended timeframes rather than instant retrieval. If agents monitor for weeks, quality signals must capture longitudinal value, not momentary relevance. Watch for: new benchmarks measuring task completion rather than retrieval speed, pricing models based on workflow success rather than query volume.
Compute allocation architectures. Systems that escalate resources based on signal strength, filtering thousands of potential sources down to the handful that matter. Srinivasan’s travel agent and the compute escalation Agrawal would describe later (10,000 URLs filtered to the 1% that produce answers) both point toward tiered processing: cheap filters followed by expensive synthesis. Watch for: infrastructure offerings specifically designed for multi-stage agent pipelines with variable compute budgets.
These signal the roadmap from infrastructure problem to economic model, from technical capability to sustainable business architecture.
Six Months Out, One Year Forward
Six months from now, expect Bright Data expanding beyond crawling toward synthesis services, not just delivering fresh data but pre-processing it for common agent workflows. DigitalOcean likely integrates more tightly with agent platforms, offering managed infrastructure for long-running monitoring tasks that current serverless models handle awkwardly.
Technologically: persistent agent architectures that maintain state across weeks or months, learning concept drift patterns rather than treating each query as isolated event.
Behaviorally: publishers experimenting with agent-specific access tiers, pricing based on data freshness requirements rather than volume retrieved.
In a year, the competitive landscape probably looks less like Google challenged by upstarts and more like layered specialization. Google maintaining dominance in general synthesis while specialized players own specific verticals where freshness requirements exceed what centralized infrastructure delivers economically. Not disruption. Unbundling.
The transformation isn’t search becoming obsolete but search infrastructure becoming ambient - embedded in every application, running continuously rather than triggered by explicit queries, optimized for machines that synthesize information over days rather than humans who glance at results for seconds.
What’s unresolved: the economic layer. Infrastructure can rebuild. Technical capabilities can scale. But until publishers and platforms negotiate sustainable value splitsm until agents both pay for access and get compensated for surfacing useful information, the architecture remains incomplete.
That negotiation began in earnest during the afternoon panel, when practitioners building these systems confronted the gaps between what’s technically possible and what’s economically viable. Infrastructure creates possibility space. Economics determines what actually gets built within it.
Companion Article:
linkedin.com/pulse/agent-economics-when-machines-become-primary-web-robert-schwentker-2zgff