
A quiet infrastructure shift assembles beneath enterprise attention. While industry debates artificial intelligence’s future, voice AI builds the coordination layer that businesses didn’t know they needed. This timing isn’t accidental - enterprise workflows have reached the point where human interface friction, not computational power, creates the bottleneck. Sequoia Capital’s Konstantine Buhler frames it precisely: “AI voice is right now” - not promise, but present reality requiring architectural thinking. “You might be surprised that I didn’t put AI video, but that’s intentional. I think that in a year AI video might be here, but AI voice is right now. And that’s because not only has its fidelity increased, the quality of voice increased to the point where it’s useful day-to-day, but the latency has decreased where you could have real time conversations with AI voice.”

Technical Assembly: Speed Meets Fidelity
Buhler’s observation cuts through hype: “not only has its fidelity increased, the quality of voice increased to the point where it’s useful day-to-day, but the latency has decreased where you could have real time conversations.” This convergence creates new enterprise bus architecture - voice as coordination protocol, not just interface layer.

Andrew Ng DeepLearning.AI surfaces a productive paradox: “Most users are better at talking than writing. Writing is a very difficult skill.” Enterprise interfaces that present “a giant text box” impose “writer’s block” - cognitive friction masquerading as user choice. Voice dissolves this friction but creates new tensions around accuracy and control.
What happens when the most natural human act becomes the most strategic enterprise interface?
OpenAI’s Architectural Choice: Integration Over Assembly
OpenAI’s GPT new real-time model makes a specific bet: speech-to-speech architecture rather than chained transcription-language-voice systems. This “natively understands and produces audio” approach trades modularity for coherence - hearing laughs, sighs, emotional undertones that text-first systems lose in translation.
Engineering specifics reveal enterprise priorities: image input support, EU data residency, asynchronous function calling. More telling: 30% accuracy on complex instruction-following benchmarks, 66% on challenging function calls. These numbers matter less than what they enable - systems that can hold conversational context while making business-critical decisions.

Peter Bakkum from OpenAI’s engineering team emphasized the model’s enterprise-grade reliability: “We’ve carefully aligned the model to production scenarios like customer support and academic tutoring.” The collaboration with production users during training represents a shift toward applied AI development, where theoretical capabilities meet real-world business requirements.
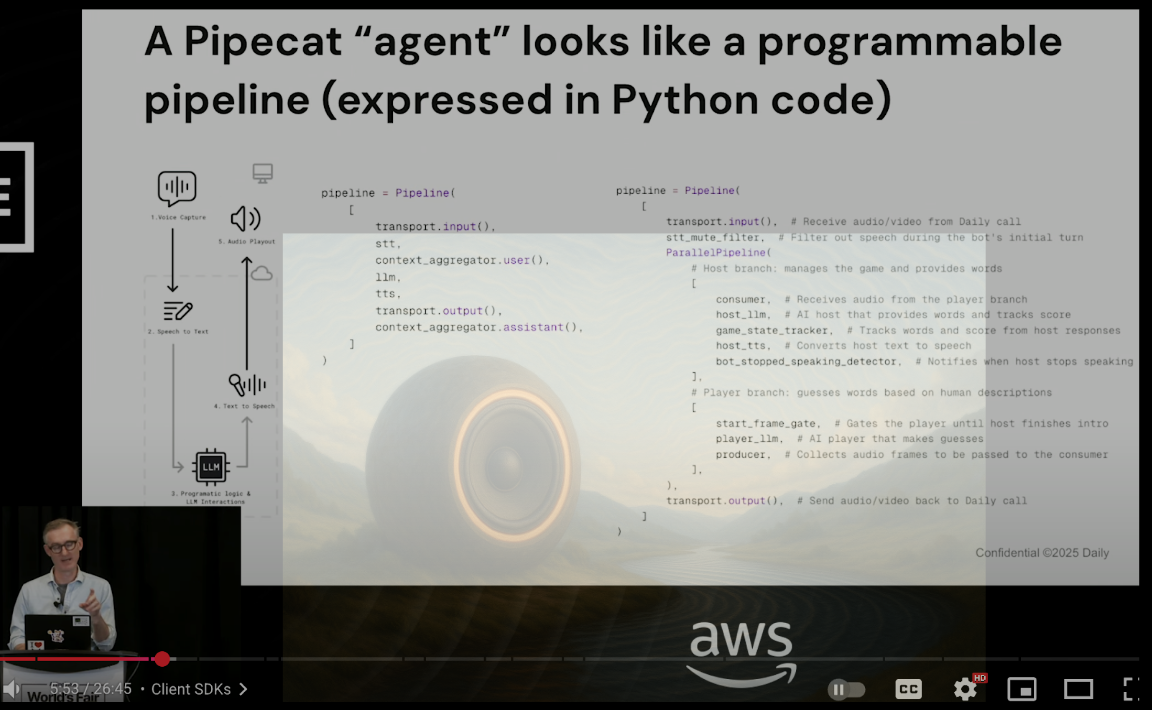
Infrastructure Philosophy: Open Assembly vs Vertical Integration
While OpenAI integrates vertically, Daily’s CEO Kwindla Hultman Kramer builds horizontally via Pipecat - “100% open source and completely vendor neutral.” This creates strategic tension: does enterprise voice AI require integrated control or modular flexibility?
Pipecat solves the assembly problem: “turn detection and interruption handling, context management, scripting, and state-machine workflow definition.” These aren’t features but foundational engineering challenges that every voice deployment must resolve. The framework’s support for “60 plus” models and services acknowledges enterprise reality - production systems rarely depend on single vendors.
User expectations create the constraint: Kramer notes humans “expect a 500 millisecond response time in natural human conversation.” Target becomes 800 milliseconds voice-to-voice - a technical requirement that reshapes entire system architectures.
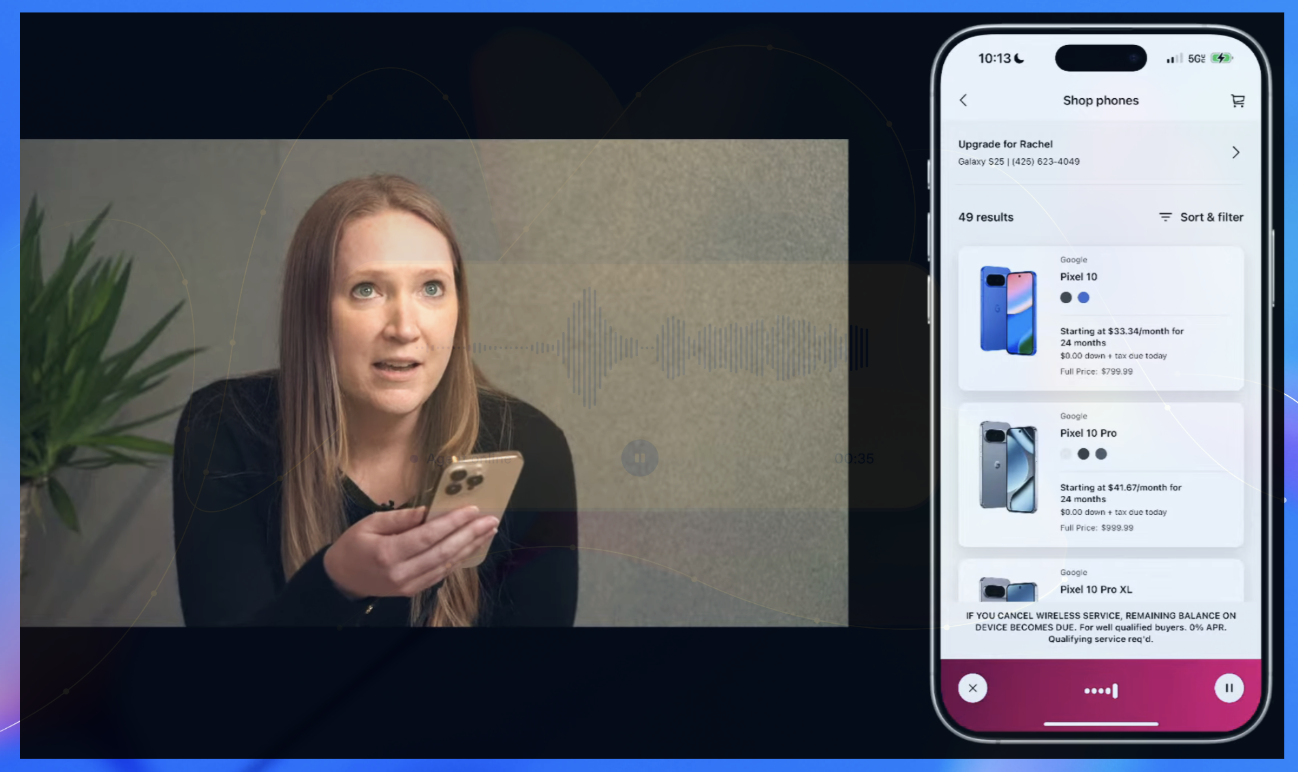
T-Mobile’s Process Reimagination
T-Mobile’s Srini Gopalan describes their voice implementation: “It’s so much more human, right? It responds - the phone upgrade process is a process where the customer could go in any direction.” This captures something deeper than automation - it’s process topology reimagined around conversational flow rather than decision trees.
The demonstration handles “random walk of multiple different questions” - exactly what traditional IVR systems cannot do. But Gopalan’s strategic insight cuts deeper: “You’re thinking about AI wrong when you take AI and try and build a 10% better IVR. You’ve got to use this technology to smash your existing processes, rebuild them from scratch.”
This suggests voice AI’s true value lies not in optimization but in architectural possibility.
Paradox: Speed vs Accuracy in High-Stakes Conversation
Andrew Ng identifies the productive tension: “a huge tension between latency where user expectations are very high for low latency versus the intelligence and accuracy, the guardrails with high stakes.” Julianne Roberson, T-Mobile’s AI engineering lead, faces this paradox directly. Her team’s implementation exemplifies the tension - customers expect instant responses, but the system cannot casually say, “Oh, absolutely. I will give you a full refund’’ without validating business policies.
Robertson’s engineering reveals the choreography behind apparent spontaneity. The AI maintains conversational flow (‘Oh, no. I’m sorry that happened’) while processing complex business logic (satellite service compatibility, plan validation). This isn’t just better customer service - it’s conversational architecture that handles both empathy and accuracy constraints simultaneously.
The paradox deepens: making machines conversational forces humans to examine what conversation actually means.
Pattern Recognition: Voice as Enterprise Coordination Layer
Buhler’s examples reveal coordination patterns: enterprise logistics “still done by voice,” fixed income trading “probably doing that over voice with an over-the-counter trading desk.” These aren’t edge cases but glimpses of voice as fundamental enterprise bus - the protocol through which complex negotiations, multi-party coordination, and context-sensitive decisions flow.
Voice AI doesn’t replace these processes but amplifies them. The technology enables automation of previously human-only coordination tasks while maintaining conversational context and business logic integration. Value creation comes from recognizing voice as architectural component, not just interface layer.
Developer Ecosystem: Composability vs Control
Pipecat’s vendor-neutral stance creates interesting tension with OpenAI’s integrated approach. Organizations must choose: controlled experience through vertical integration or compositional flexibility through open frameworks. Neither choice is purely technical - each reflects different theories about how enterprise voice systems should evolve.
Specialized hosting solutions like Pipecat Cloud indicate market confidence in sustained demand. Multi-platform SDKs (JavaScript, React, iOS, Android) suggest voice interfaces becoming standard enterprise software components rather than specialized telephony features.
The architecture question becomes: do enterprises build on integrated platforms or assemble modular components? Market will likely reward both approaches for different use cases.
Assembly Complete: What Voice Reveals
Voice AI’s maturation exposes something unexpected about enterprise architecture. The most natural human interface - speech - becomes the most strategic business protocol. This creates productive tensions across organizational layers.
Enterprise leaders face architectural questions: when customers expect to speak naturally to websites rather than navigate menus, how does digital infrastructure adapt to sound as primary interface language? Board members must establish governance for AI systems making real-time decisions affecting brand reputation and regulatory compliance.
Builders confront technical paradox: architecting systems that maintain conversational state across interactions while integrating with existing enterprise data flows. Educators discover pedagogical possibilities when textbooks become conversational partners adapting explanations to vocal cues and learning patterns.
But the deeper question surfaces for everyone: why does achieving natural human-AI interaction require us to become more conscious of what makes human conversation uniquely human?
Voice AI doesn’t just enable new capabilities - it forces reflection on conversation itself. As machines become more human-like through speech, humans must examine what conversation actually means, how context flows, what listening involves. The technology succeeds by making us more thoughtful about our most fundamental communication act.
This is voice AI’s true contribution: not just better interfaces, but deeper understanding of interface itself.

Sources:
• Sequoia Capital - Konstantine Buhler: “Investment Theme #3: AI Voice” (Aug 28, 2025) - https://www.youtube.com/watch?v=yoycgOMq1tI&t=671s
• Andrew Ng: “Architecting Multi-Agent Systems” - Hypergrowth Engineering Summit 2025 (Aug 21, 2025) - https://www.youtube.com/watch?v=yi7doi-QGJI
• OpenAI: Speech-to-Speech Model Demo w/ Brad Lightcap, Peter Bakkum, et al. (Aug 28, 2025) - https://www.youtube.com/watch?v=nfBbmtMJhX0&t=882s
• Daily: “Pipecat Cloud: Enterprise Voice Agents” - Kwindla Hultman Kramer (Jul 31, 2025) - https://www.youtube.com/watch?v=IA4lZjh9sTs
OpenAI Realtime voice api
https://platform.openai.com/docs/guides/realtime
