
Insights from the Arize Observe 2025 Agent Frameworks Panel
By 9 AM, seven hundred people had filled the Ferry Building’s main hall. They had come to see five founders, each representing a different theory of how machines should think, attempt to define the undefinable while maintaining the kind of collegial politeness that masks serious intellectual combat.
The Ferry Building conference hall contained the kind of crowd that might later be recognized as present at a pivotal moment: engineers, researchers, and executives who had staked their careers on the proposition that software could learn to act with genuine autonomy. What they were about to witness was something between a panel discussion and a careful dissection of the industry’s fundamental assumptions. As companies accelerate from prototype to production with AI agents, the frameworks they choose today may well determine their competitive positioning for the next decade, yet the field remains energetically divided on questions as basic as what constitutes an “agent” and whether current frameworks represent breakthrough innovation or sophisticated abstraction layers.
Defining the Undefined: What Makes an Agent?
The panel opened with a deceptively simple question from moderator Aparna Dhinakaran, Founder & CPO of Arize, that revealed immediate fault lines. When asked to define an “agent,” the responses ranged from philosophical to pragmatic, each reflecting different technical and business priorities.
João (Joe) Moura, CEO of CrewAI, cut straight to the core: “For me, an agent is all about agency. As long as AI is controlling the flow of the application… there’s AI helping with the planning, helping with the learning, helping with the execution, deciding what to actually create, that’s where it feels like an agent has life.”
Jerry Liu, Co-Founder and CEO of LlamaIndex, offered a more taxonomic view: “There’s really kind of two main types of agents. One are basically the types that help automate routine tasks for you… automation-based agents. And then the other type are basically those that provide you information that help you make better decisions.”
But it was Abhi Aiyer, Co-Founder and CTO of Mastra, who delivered perhaps the most provocative take: “Agent frameworks are essentially a collection of tools that get you further faster. It’s the only reason to use them. And right now, research and production are actually equals… there’s no really difference. Things that are in research papers you’re seeing in the wild the next day.”
Charles Packer, Co-Founder and CEO of Letta, brought both historical perspective and academic provocation from his Berkeley PhD research background. Having worked on what people called agents before ChatGPT, training robots that “fell over a million times” before learning to get up, he offered perhaps the panel’s most pointed critique: “I think agent today has completely lost all meaning.” Yet he acknowledged the fundamental shift: “What really changed post-ChatGPT is that the environmental intelligence became much more general. So I was working on agents in 2017-2018, you would have to train a new agent for every task… Today we have the same models that are incredibly general.”
The definitional chaos reveals a deeper strategic question: Are we witnessing the emergence of a new computing paradigm, or are we simply rebranding existing automation tools with more sophisticated natural language interfaces? The answer may determine which companies build sustainable moats and which find themselves commoditized.

The Framework Fracture Lines
As the conversation shifted to framework architectures, clear battle lines emerged. The panelists described an ecosystem splitting along several dimensions that will likely determine long-term market structure.
Packer outlined the fundamental divide: “I would say there’s two sorts of frameworks. There’s low-code stuff like LangGraph, LlamaIndex LangGraph, where you’re constructing these graphs effectively. And then there’s AutoGPT-style stuff where it’s really about just putting the language model in some sort of loop and giving it access to the entire computer.”
This architectural split reflects deeper philosophical differences about control versus autonomy. Graph-based frameworks offer predictability and debugging capabilities that enterprises demand, while loop-based approaches promise greater flexibility at the cost of reliability, a classic engineering tradeoff that becomes a business strategy decision.
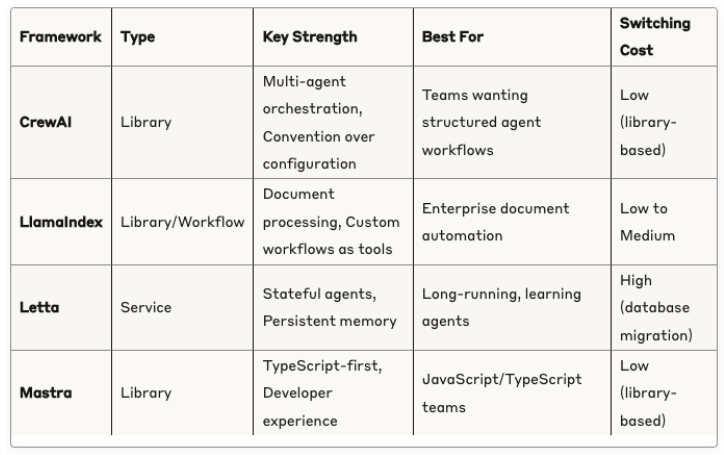
But Packer identified another crucial distinction that may prove more consequential: “There’s a difference from an engineering perspective on service versus library. Most agent frameworks are really libraries… but to switch from one service to another service where there’s a database model, you have to migrate the schema. That’s very hard.”
This observation hints at a potential lock-in dynamic that could determine market winners. Library-based frameworks enable easy switching but limit functionality, while service-based frameworks create switching costs but offer richer capabilities. As Packer explained: “By nature of the library, not holding memories inside it, not holding messages, it’s very easy to switch from one library framework to another library framework. You just have to rewrite your script. But to switch from one service to another service where there’s a database involved, you have to migrate the state.”
The question becomes whether developer convenience or feature depth will drive adoption decisions, and whether companies will find themselves locked into architectural choices they made during early experimentation phases.
Liu acknowledged this tension while defending LlamaIndex’s workflow approach: “We offer both low and high levels of abstraction. Developers typically like a lot of flexibility… the other thing I’d add is, what’s the difference between this and Temporal or Airflow? It’s basically just a few things.”
The comparison to traditional orchestration tools raises uncomfortable questions about differentiation. If agent frameworks are primarily workflow engines with LLM integration, what prevents established players from entering the market?
Aiyer pushed this logic to its provocative conclusion with a seemingly offhand comment that cut deeper than it appeared: “What open source library do you know that has joined the Linux Foundation this past year? That’s where products essentially go out to pasture.” The implication was unmistakable, institutionalization as the death of innovation, a warning shot for any framework considering the respectability of standards bodies over the chaos of genuine progress.
The answer to competitive differentiation may lie in specialized capabilities that only emerge from deep agent-specific optimization, but the specter of commoditization looms large.
The Language Divide and Framework Futures
A more fundamental architectural question emerged around language support and specialization. Aiyer offered a framework philosophy that borrowed from web development’s evolution: “There’s no JavaScript version of Rails, maybe it’s called Next.js, but like… for a framework to take care of language-specific features of that framework, to optimize for the deployment of that language… if you’re going to build multi-language, that means you have to have a share of your skill and your team to then support both languages.”
This insight reveals a potential fracture in the framework landscape. Rather than universal solutions, the market may evolve toward language-specific optimizations, a go framework here, a TypeScript framework there, each tuned to the deployment patterns and developer ergonomics of its ecosystem. The implications for companies betting on particular technology stacks could be significant.
Perhaps no topic generated more heat than multi-agent architectures. The discussion revealed a fascinating paradox: while multi-agent systems represent the most sophisticated expression of agentic AI, they may also be the least practical for most current use cases.
Packer offered a nuanced take that cut through the hype: “Multi-agent is really a form of prompt engineering. It’s a way for you to encode more structured knowledge into your agentic system… it’s not coming from the fact that the model or the system is not good enough to do everything, because I think Claude 3.5 Sonnet and GPT-4, they will be able to role-play as many agents.”
This insight exposes a potential dead end in current multi-agent thinking. If foundation models become sufficiently capable of internal role-switching, the complexity overhead of multi-agent architectures may not justify their benefits. Yet Moura pushed back with a systems perspective: “I think it’s more about service decomposition and economization… if you believe in microservices, you’ve seen how companies scale and how they’re composing their systems into smaller pieces.”
The parallel to microservices architecture is instructive but potentially misleading. Microservices emerged to solve specific scaling and organizational problems in software development. Do AI agents face analogous challenges, or are we applying familiar patterns to fundamentally different problems?
Liu grounded the discussion in practical reality: “A lot of enterprise and area workflows… it’s a sequence of steps, and you use LLMs in the middle to do reasoning, but the overall orchestration is still a little bit more constrained… that stuff works more right now.”
This pragmatic view suggests that current multi-agent deployments may be solving workflow orchestration problems rather than creating truly autonomous agent swarms. The distinction matters enormously for companies evaluating their agent strategies.

Protocol Dynamics and Platform Plays
The emergence of MCP (Model Context Protocol) and A2A (Agent-to-Agent) protocols sparked particularly revealing exchanges about platform control and ecosystem development. The panelists’ reactions exposed different theories about how the agent ecosystem will evolve, and who will control it.
Aiyer delivered perhaps his spiciest take on A2A: “It’s a glorified task system, so you can just use Temporal. You could probably achieve the same thing, so I don’t know why that’s an A2A protocol.”
Moura was more diplomatic but equally skeptical about the motivations: “A lot of the hyperscalers, they look at it like, ‘Hey, if you control these protocols, it gives you an edge in the market’… you can see how A2A is so intertwined with Google stuff. It’s a little weird, a little creepy.”
The subtext here is crucial for strategic planning. Protocol standardization could commoditize agent frameworks by creating interoperability, but it could also create platform advantages for protocol controllers. The battle over agent protocols mirrors earlier fights over web standards, mobile platforms, and cloud APIs.
Packer offered a more optimistic view of MCP while remaining skeptical of A2A: “MCP, even when it came out, solved a problem that everyone wanted solved. Everyone’s like, ‘I have that problem,’ and MCP is the solution… A2A is more like a solution looking for a problem that’s not here yet. Maybe the problem’s like a few months from now, like a year from now… or never.”
This assessment suggests that successful protocols must emerge from genuine developer pain points rather than top-down platform strategies. For companies building agent capabilities, the lesson may be to focus on solving immediate problems rather than betting on speculative standards, particularly when those standards carry the fingerprints of platform companies with their own strategic agendas.

The Evaluation Enigma
As the conversation turned to evaluation strategies, it revealed another fundamental tension in the agent ecosystem: the gap between what companies think they need and what actually drives success.
Aiyer shared revealing insights from recent customer interactions in Japan: “They picked evals as the moat that separates their product from others, and so they’re heavily invested in evals. But they don’t know how to do them… When you’re getting started with agents, you’re not writing evals at all…you’re vibe debugging. When you’re getting into production, you start writing custom evals, maybe not the ones off the shelf.”
This observation highlights a critical maturity curve that many companies may be navigating incorrectly. The temptation to focus on sophisticated evaluation frameworks before achieving basic functionality could be a strategic error that misses the essential progression from experimentation to production deployment.
Packer delivered perhaps the panel’s spiciest take on evaluations, drawing from his academic background: “I think evals are currently a little bit overrated… I’ve seen customers who are really pushing the frontier of what you can do with these great models, they don’t have beautiful eval setups and they’re not doing evals at all. They’re YOLOing it, trying to get as much juice out of the current models.”
The “YOLO” comment sparked nervous laughter but touched on a deeper truth about the current state of agent development. Packer’s academic analogy was illuminating: “When I was a PhD student, there’s probably two types of AI papers… you’ve got to decide, ‘In the next few months I’m gonna write a benchmarking paper or I’m gonna write a methods paper.’ The benchmarking paper would be something you do if you don’t really necessarily have the idea yet for what your new methods would be… it’s kind of like this yin-yang where you do the benchmarking and you do the new method.”
If the most successful deployments are happening without sophisticated evaluation frameworks, what does that say about the industry’s current priorities? The academic parallel suggests that evaluation may be most valuable as a diagnostic tool for identifying problems rather than as a competitive moat in itself.
Liu offered a middle path: “Evals are important because that’s how you iterate and improve… there’s accuracy and there’s accuracy with human in the loop… it’s way worse if you just spray and pray versus if humans actually have a chance to correct it.”
This human-in-the-loop insight may be the key to resolving the evaluation paradox. Rather than pursuing fully autonomous evaluation systems, the path forward might involve sophisticated human-AI collaboration frameworks.
The Abstraction Controversy
The panel tackled head-on what may be the most contentious debate in the space: whether agent frameworks represent genuine innovation or merely sophisticated abstractions that developers should avoid. The moderator’s call for spicy answers finally unleashed the full force of the industry’s philosophical tensions.
Aiyer drew from his experience at Gatsby JS to defend the educational value of frameworks: “Most of the users, they didn’t know how to build websites in React… So they’re using a framework to learn something, and then maybe all those users graduated and then did their own thing later… Frameworks definitely are there to help introduce you to concepts and then kind of guide you. You don’t have to think about what exists, you just do what we tell you to do, and then eventually you start thinking for yourself.”
Moura offered a Rails-inspired defense that cut to the core of framework value: “I know it’s faster for you to get a website nowadays more than Rails… That has pros and cons. The reason why they have to do it is because they heavily rely on convention over configuration… as long as you stick with that Rails convention, you’re gonna get very fast development and get out of your way. But then that means if you’re gonna get out of those Rails, then it makes it extra hard.”
The Rails analogy reveals the fundamental tradeoff: frameworks accelerate development within their conventions but create friction when requirements exceed their assumptions. In an industry moving as fast as AI, the question becomes whether the learning curve shortcuts justify the eventual constraints.

Strategic Implications and Future Trajectories
As the panel concluded with rapid-fire predictions, each founder revealed their theory of how the market will evolve, insights that carry significant implications for companies planning their agent strategies.
Aiyer’s prediction carried subtle implications about market maturity: “I’m really excited for people outside of San Francisco to discover that agent frameworks exist.” This comment suggests that the current ecosystem may be experiencing a Silicon Valley bubble, with broader enterprise adoption still ahead. Companies in other markets may have opportunities to leapfrog current approaches rather than follow the Valley’s experimental patterns.
Packer offered the most technically ambitious prediction: “Right now when people look at agents, they’re very ephemeral. They kind of run workloads… towards the back half of this year, we’re going to see more and more stateful agents with production workloads that actually accumulate knowledge over time.” This vision of persistent, learning agents represents a significant evolution from current stateless approaches and could fundamentally reshape how organizations think about agent deployment and lifecycle management.
Liu focused on democratization: “I’m really excited for non-technical users… because I think we’re gonna see way more of those cursor-type things.” The implication is that the framework wars may be less important than the broader accessibility of agent creation tools.
Moura delivered the panel’s final provocation: “I think people will stop using the word ‘agents’ and people will call them ‘automators.’” This prediction suggests that the current agent hype may give way to more pragmatic framing focused on business outcomes rather than technical sophistication, a shift that could determine which companies build sustainable value versus those caught up in terminology trends.
Navigating the Strategic Landscape
The panel discussions reveal several critical decision points for organizations building agent capabilities:
The Framework Selection Paradox: Companies face a choice between flexibility and functionality. Library-based frameworks offer easy switching but limited capabilities, while service-based frameworks provide richer features but create switching costs. The decision may depend on whether an organization views agents as experimental tools or core infrastructure.
The Abstraction Question: The debate over whether frameworks are “just abstractions” misses a deeper point about organizational capabilities. Frameworks may be most valuable not for their technical sophistication but for their ability to encode best practices and reduce cognitive load for development teams.
The Multi-Agent Trap: The allure of multi-agent architectures may distract from simpler, more effective solutions. Organizations should consider whether their use cases truly require agent-to-agent communication or whether single-agent workflows with human oversight might be more appropriate.
The Evaluation Investment Timing: The tension between sophisticated evaluation frameworks and rapid iteration suggests that evaluation strategies should evolve with deployment maturity. Early-stage efforts may benefit more from rapid prototyping than comprehensive testing infrastructure.
Partnership vs. Platform Strategies: The emergence of protocols like MCP creates opportunities for both integration and differentiation. Companies must decide whether to bet on protocol standardization or proprietary approaches based on their competitive positioning and technical capabilities.
Critical Questions for the Road Ahead
The panel discussions raise several questions that will likely determine the trajectory of the agent ecosystem:
Can foundation models eliminate the need for multi-agent architectures? If models become sufficiently capable of internal role-switching and context management, the complexity overhead of multi-agent systems may become unjustifiable. This could reshape the entire framework landscape.
Will evaluation frameworks become competitive moats or commodity utilities? The Japanese market’s focus on evaluation as differentiation suggests one path, but the panelists’ skepticism about current approaches suggests another. The resolution may determine which companies capture value in the agent stack.
Do agent frameworks represent genuine innovation or sophisticated middleware? The comparison to traditional workflow engines raises questions about sustainable differentiation. Frameworks that solve agent-specific problems may thrive, while those that simply wrap existing capabilities may struggle.
How will the service vs. library divide shape market structure? The tension between flexibility and functionality could create different market segments with different winners. Understanding which approach aligns with organizational needs and capabilities will be crucial.
What role will protocols play in ecosystem evolution? The success or failure of standardization efforts like MCP and A2A could determine whether the agent ecosystem remains fragmented or consolidates around common standards.
The Capital Efficiency Imperative
Underlying all these technical discussions is a fundamental business question: which approaches to agent development offer the best return on investment? The panel revealed significant disparities in resource requirements across different frameworks and architectural approaches.
Service-based frameworks require ongoing infrastructure investment but offer richer capabilities and potential platform effects. Library-based approaches minimize operational overhead but may require more development resources to achieve equivalent functionality. Multi-agent architectures promise sophisticated capabilities but at the cost of increased complexity and debugging challenges.
For organizations with limited AI/ML expertise, framework selection becomes a build-versus-buy decision with significant implications for team structure and capability development. The choice between learning curve simplicity and ultimate flexibility may determine both short-term success and long-term strategic positioning.
The evaluation paradox adds another layer of complexity. Sophisticated evaluation frameworks require significant upfront investment but may not drive near-term value. Organizations must balance the need for quality assurance with the imperative for rapid iteration and market feedback.
Conclusion: Embracing Productive Uncertainty
The Arize Observe 2025 agent frameworks panel revealed an ecosystem in productive flux. While the fundamental questions about agent architectures, framework selection, and evaluation strategies remain unresolved, the quality of the debates suggests that the industry is grappling with the right problems.
For organizations building agent capabilities, the key insight may be that there are no universally correct answers, only approaches that align with specific contexts, capabilities, and objectives. The framework wars are not about identifying a single winner but about understanding how different approaches serve different strategic needs.
The most successful organizations may be those that embrace this uncertainty while maintaining clear decision-making criteria. Rather than seeking the perfect framework, they might focus on rapid experimentation, clear success metrics, and organizational learning capabilities that enable adaptation as the ecosystem evolves.
As Moura’s final prediction suggests, the current focus on “agents” may give way to more pragmatic discussions about automation and augmentation. But the strategic and technical foundations being laid today, through framework choices, architectural decisions, and evaluation approaches, will likely determine which organizations thrive in that more mature landscape.
The agent framework landscape continues to evolve rapidly, but the key decisions are becoming clearer. Like the early days of computing when MS-DOS, OS/2, Windows, and Mac competed for dominance, today’s agent frameworks are in a similar consolidation phase. Just as the OS competition ultimately wasn’t won by the most technically elegant solutions but by factors like business partnerships, timing, and ecosystem effects, what will determine the agent framework winners remains an open question: pure developer adoption, breakthrough consumer applications, platform backing, or some combination we haven’t yet seen? Success may belong not to those who choose the perfect framework, but to those who can see patterns emerging from complexity, riding the waves of innovation while helping their organizations anchor decisions in what will endure beyond the current technical turbulence.
The author has extensive experience covering AI infrastructure and enterprise technology adoption. This analysis is based on direct observation of the Arize Observe 2025 panel discussion and ongoing research into the agent framework ecosystem.
Appendix
A. Key Questions for Companies Evaluating Agent Strategies
Maturity Assessment:
-
Organizations might consider whether they remain in exploratory phases or are moving toward production-scale deployment, a distinction that could influence framework selection criteria.
-
The presence or absence of dedicated AI/ML engineering expertise may determine whether framework-guided learning becomes valuable or potentially constraining.
Architectural Decisions:
-
Stateful agents that accumulate knowledge over time might represent a different architectural commitment than ephemeral task-based systems, each path potentially carrying distinct scaling implications.
-
Agent deployment models often split between routine task automation and decision-support information provision, a choice that may shape both technical requirements and organizational integration patterns.
-
Multi-agent coordination versus single-agent workflows could represent more than a technical preference, perhaps reflecting different approaches to complexity management and system reliability.
Technical Strategy:
-
Primary development language and framework language-specificity might create subtle lock-in effects that could compound as teams develop expertise and tooling around specific ecosystems.
-
The library flexibility versus service convenience tradeoff may reveal deeper questions about organizational control, vendor dependence, and long-term architectural evolution.
-
The progression from “vibe debugging” to production-grade evaluation systems could indicate whether organizations can scale beyond prototyping or might remain in extended experimentation phases.
Business Positioning:
-
Building general agent capabilities versus encoding company-specific processes might represent different theories of competitive advantage, each potentially requiring distinct investment strategies and organizational capabilities.
-
Competitive differentiation through framework choice versus domain-specific tooling may reveal where value creation actually occurs in the agent stack.
-
Emerging protocols like MCP could present strategic considerations about platform integration versus proprietary control, choices that might influence ecosystem positioning for future technology cycles.
B. Timeline of Predictions and Milestones per Panelists
Near-term (6-12 months):
-
Framework consolidation in library space as developer preferences solidify
-
Increased adoption of MCP for tool integration
-
Shift from experimental multi-agent architectures to constrained production workflows
Mid-term (Back half of 2025):
-
Emergence of stateful, persistent agents in production environments
-
Greater democratization through low-code/no-code agent creation tools
-
Enterprise adoption beyond Silicon Valley early adopters
Longer-term Trends:
-
Potential terminology shift from “agents” to “automators” as market matures
-
Language-specific framework specialization (following Rails model)
-
Integration of reinforcement learning for continuously improving agents
Uncertain/Speculative:
-
Role of A2A protocols (may emerge later or never gain traction)
-
Degree of framework standardization vs. continued fragmentation
-
Impact of foundation model improvements on multi-agent architecture relevance
C. Glossary of Technical Terms
Agent: An AI system with agency, where artificial intelligence controls the application flow, participates in planning, learning, and execution decisions, and determines what to create or do next. Panelists identified two main types: automation-based agents that handle routine tasks, and information-based agents that provide decision-support data. The term has “completely lost all meaning” in current usage according to some panelists, yet represents a fundamental shift from pre-ChatGPT systems that required task-specific training to today’s general-purpose models that can adapt across domains. Distinguished from simple LLM applications by the AI’s autonomous control over workflow and decision-making processes.
Agent Framework: Software library or service that provides tools and abstractions for building AI agents, handling common requirements like memory, tool integration, and workflow orchestration.
Agentic: Describing AI systems that can take autonomous actions and make decisions, rather than simply responding to direct prompts.
A2A (Agent-to-Agent) Protocol: Proposed standard for how different AI agents communicate and coordinate with each other. Currently more theoretical than practical.
Context Engineering: Building dynamic systems to provide the right information and tools in the right format such that the LLM can plausibly accomplish the task. Unlike static prompt engineering, this involves creating systems that dynamically assemble context from multiple sources including user inputs, tool outputs, memory systems, and external data.
Evaluation (Evals): Systematic testing and measurement of AI agent performance, ranging from simple accuracy metrics to complex custom assessments tailored to specific business objectives.
Library vs. Service Framework: Libraries integrate into your codebase with low switching costs but limited functionality; services provide richer features but require data migration to switch.
MCP (Model Context Protocol): Standard for how AI agents interact with external tools and services, enabling better interoperability across different systems.
Multi-agent Architecture: System design using multiple specialized AI agents that coordinate to complete complex tasks, as opposed to single-agent approaches.
Prompt Types: Different categories of prompts used in agent systems including user prompts (direct requests), system prompts (behavioral instructions), agent prompts (internal reasoning), evaluation prompts (performance testing), tool prompts (function calling), memory prompts (context retrieval), and chain-of-thought prompts (step-by-step reasoning).
Self-Improving Prompts: Dynamic prompt systems that automatically refine their instructions based on performance feedback, error analysis, and interaction patterns, enabling agents to optimize their own communication with language models over time.
Stateful vs. Ephemeral Agents: Stateful agents retain memory and learning across sessions; ephemeral agents start fresh each time and don’t accumulate knowledge.
Tool Calling: The ability for AI models to invoke external functions, APIs, or software tools to gather information or perform actions beyond text generation.
Vibe Debugging: Informal term for testing AI agents through direct interaction and observation rather than formal evaluation frameworks, common in early development phases.
Workflow Orchestration: Managing the sequence and coordination of multiple steps or processes, often involving both automated systems and human oversight points.
E. Additional Reading
Technical Deep Dives:
-
The Rise of Context Engineering - How dynamic context systems are becoming more important than prompt engineering for agent reliability
-
Andrew Ng on Agentic Workflows - The AI pioneer’s perspective on why agents represent a fundamental shift in AI application patterns
Production Implementation:
- Blueprints for the Agentic Era: Inside the Revolution Transforming Enterprise AI - Hands-on workshop insights from Jerry Liu (LlamaIndex) and João Moura (CrewAI) on building production-ready agent systems, featuring real-world implementations and cost economics
https://bsky.app/profile/schwentker.bsky.social/post/3lskoj7ycoc2n