
One April evening in San Francisco, the AWS Gen AI Loft filled with builders, founders, and investors looking for more than pitches—they came to see what’s next. Hosted by Arte Merritt, Amazon Web Services (AWS), the event featured a curated run of live demos that made one thing clear: generative AI is shifting from concept to creation.
This wasn’t about frameworks or syntax. It was about feel. About flow. Vibe coding was in the air—AI systems responding to intent, not instruction.
What followed was a fast-moving tour of tools reshaping how we imagine, build, and share—from browser agents and speech models to video generation and content search. A glimpse 🎥 at how generative AI is becoming a creative platform in its own right. Not the future—now.
AWS Bedrock: The Foundation Layer
The demonstrations began with Jean Malha, AWS Generative AI Specialist, who established the conceptual ✨ framework for the evening by outlining Bedrock’s architectural principles.
“Bedrock is a fully managed service that makes it easier to build, deploy, and maintain generative AI applications,” Malha explained, gesturing toward the packed room. “There are three key tenets to remember about Bedrock. The first is model choice—even in this region, we have fifty foundation models to choose from, and we provide a marketplace that includes open source models.”
Malha continued by highlighting Bedrock’s extensive built-in functionality: “The second key tenet is all the features and functionality we provide—knowledge bases, guardrails, intelligent front routing—all things that are built-in if you don’t want to build them yourself.”
Perhaps most critical for enterprise adoption, Malha emphasized Bedrock’s approach to data sovereignty: “The third thing, and it’s the most 🔑 important, is the data privacy and security. If you’re using Bedrock, you can rest assured that it’s your data. It’s not coming back to any undecided auto provider. We’re not going to use it, the model providers can’t use it.”
This reassurance—that enterprises can leverage advanced AI capabilities without compromising data sovereignty—represents a significant maturation in the AI implementation landscape, addressing what has been a primary barrier to adoption among security-conscious organizations.

Nova App: Reimagining Browser Automation
First came Nova App, which was described as “a new SDK and model for browser use” 🧾 The demonstration revealed a remarkably 🔮 streamlined approach to browser automation—with just 64 lines of code, an agent was programmed to search for a specific book on Amazon, add it to the cart, and report back the price, all without explicitly defining the navigation paths.
“It’s a fantastic way to work with browsers,” he explained. “You get your entire results without having to specify how the application should be navigated. I find it a great way to test my applications without having to rely on creating DevOps scripts.”

The implications extend far beyond simple e-commerce automation 🛒. For developers, Nova App presents a paradigm shift in how we approach UI testing and interaction with web interfaces—moving from brittle, explicit navigation scripts to intent-based interaction models that can adapt to changing interface elements. For business stakeholders, it represents a democratization of automation capabilities, potentially reducing the technical barriers to process optimization.
When asked if Nova App could be tested locally without deployment to a public server, he clarified: “All of the browser rendering is done on my laptop, but the inferencing of the foundation model happens through the Nova App service. It’s currently in research preview—you can go to nova.amazon.com, sign in with your Amazon account 🗝️, get an API key, and use it.”
Nova Sonar: Speech-to-Speech AI Interaction 🎤
The second demonstration showcased Nova Sonar, a speech-to-speech model enabling natural bi-directional conversations. He initiated a simple exchange, asking the model to welcome everyone to the Bedrock demo night. Without hesitation, a natural-sounding voice 🎙️ responded: “Hey everyone, welcome to the Build on Bedrock demo night. I’m thrilled to see so many talented folks here. Let’s make this an unforgettable evening.”
What distinguished this interaction wasn’t just the quality of the voice synthesis, but the conversational 🌊 fluidity. When asked about travel options from San Francisco to Seattle, the model responded contextually. When the follow-up question pivoted to hotel bookings, the AI seamlessly shifted context: “Absolutely! I’d be happy to help you book a hotel in Seattle. Can you tell me your preferred dates and any specific requirements?”
“What’s interesting here,” he observed, “is that you have a model with two views that has the ability to interact with your user naturally ✨, switching with a very natural voice. And it’s integrated with Bedrock without having to deploy anything.”
This demonstration highlighted how rapidly we’re approaching a new paradigm of human-computer interaction—one where the rigid command structures and unnatural interfaces that have defined computing for decades give way to more intuitive, conversational exchanges that align with natural human communication patterns.
Following this introduction, Arte set the stage for the demos, bringing on the first of two powerful applications of generative AI across video, image, music, and sound—signaling a turn toward more natural 🍃 interfaces.

Visual Storytelling: Luma AI
The next demonstration shifted the focus from interaction to visual storytelling, with Jesse Gillette from Luma AI taking the stage. Having previously led Partnerships & Business Development at Spotify, Gillette brought both artistic sensibility and business acumen to her presentation of Luma’s foundation models—Photon for images and Ray for video.
“We are an image and video foundation model company based in Palo Alto,” Gillette began. “We have two main 🧩 foundation models: Photon is our image foundation model, and Ray is our video model.”
Gillette explained how the company pivoted from its origins in 3D modeling technology: “The company was originally founded on the idea of NeRF, which is a 3D modeling technology that was written by a research scientist out of Berkeley named Matt, who now works at Luma. We pivoted about two years ago to be an image and foundation model company.”

What distinguishes Ray from other video models, Gillette emphasized, is its exceptional handling of multimodal reasoning, physics, 🧬 anatomy, and contextual coherence: “We’re doing a lot of smart things on the back end of our model when we have very simple natural language prompts. It’s very complicated what we’re sending and retrieving for you in real time. You don’t have to be a prompt engineer to use Luma.”
The demonstrations were remarkable in several dimensions. Using a simple prompt—“a realistic polar bear swimming underwater”—Gillette generated video clips showing remarkably fluid motion and natural physics. The fur moved believably underwater, creating an uncanny sense of realism from a simple text prompt. With minimal effort, she added ambient audio, transforming the clip into something that could feasibly appear in a nature documentary.

Perhaps most impressive was Ray’s ability to maintain character consistency throughout videos: “One standout feature in Luma is character reference. You can take existing assets you have, or create a character from text. In this case, I actually made this character from text prompting, referenced it by just tagging ‘@character’, and now Luma knows to keep that character consistent throughout an exceptionally 🧵 long video.”
For filmmakers, producers, and brand marketers, this technology enables precise visual direction through natural language, dramatically reducing the resources required for certain types of production. Gillette noted: “What we’ve heard from indie filmmakers is that this saves them about 70% of costs on things like B-roll, background footage, texture layering, and reshoots.”
The implications extend beyond cost savings to enabling entirely new creative workflows—where directors can rapidly iterate on visual concepts, explore staging options, and experiment with different emotional tones without the traditional resource constraints of visual production. The technology’s ability to maintain visual consistency throughout sequences represents a solution to narrative continuity challenges that typically require expensive and time-consuming post-production work.
Intelligent Content Analysis: Twelve Labs
Following Luma’s generative approach Travis Couture from TwelveLabs presented a complementary technology addressing a different but equally significant challenge—making existing video content discoverable and useful. As Director of Solutions Engineering, Couture articulated the problem his company aims to solve: “Most of the world’s data is video. Most of it is completely undiscoverable. It’s buried away, there’s so much of it, it’s really hard to deal with.”
To address this challenge, Twelve Labs has developed two foundation models with distinctly equestrian names. “We have two different foundation models that we call Marengo and Pegasus,” Good explained. “Marengo 2.7 is our embedding model, and Pegasus is our video-to-text model.”

For those unfamiliar with embeddings, Couture offered an accessible explanation: “If I say ’think of a scene where the main character is trying to decide between a red pill and a blue pill,’ probably the majority of you will think of The Matrix. How you did that is actually really amazing. If you think about all the video content you’ve ever watched, all the memories you have, you immediately took my natural language description of that scene and retrieved it from your memory. Human memory is sort of a rough analog to embeddings.”
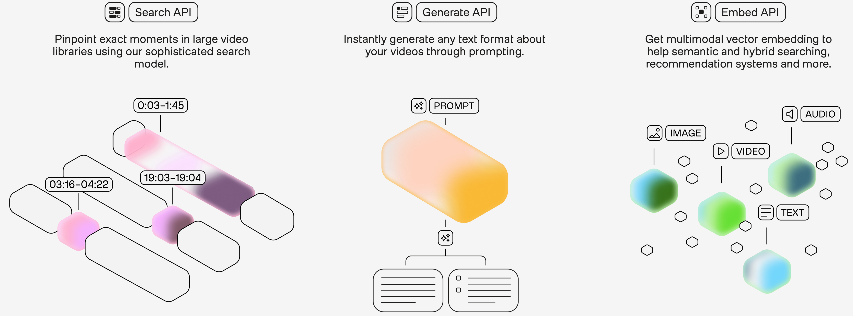
The demonstration showcased how Marengo enables multimodal search across video libraries. In one example, Couture searched for “somebody doing a front flip” and the system not only identified the relevant video but pinpointed the exact segment (seconds 31-42) where the action occurred—a critical capability when working with long-form content.
More impressive was the system’s ability to accept non-textual search inputs. When Travis uploaded an image of an Uno reverse card, Marengo returned a video of a player receiving a yellow card from a referee and then pulling out an Uno reverse card—demonstrating the model’s understanding of visual semantics beyond simple object recognition.

“All of this is done from a single 🔄 processing of the video,” Couture emphasized, highlighting a key technical advantage. “In traditional methods, you have to process the video every time you want to run a query. Dumping video into text format is an extremely lossy conversion process—you lose a lot of information that’s really relevant that you might want to reuse later.”
Travis concluded with a compelling future vision: “We’ve announced that Twelve Labs video foundation models will be available in Bedrock coming soon, so you’ll be able to access this as a managed service. This will be serverless—you won’t have to worry about spinning up and managing the infrastructure yourself.”
For media companies, these capabilities offer revolutionary approaches to content discovery, rights management, and archival research—potentially transforming how organizations leverage their existing visual assets and unlocking value from previously inaccessible content libraries.
Reflections on the Convergence of Technology and Expression
As the demonstrations concluded and attendees began discussing what they’d witnessed, several profound questions emerged about the implications of these technologies. Three questions in particular seem to capture the transformative potential—and the philosophical dimensions—of what was showcased:
1. Are we witnessing the collapse of the technical barrier as the primary constraint on creative expression?
Throughout history, creative vision has been constrained by technical execution—what we can imagine has always exceeded what we can realize. These technologies suggest a future where that gap narrows dramatically. When natural language can generate sophisticated visual narratives, when complex interfaces respond to human intent rather than explicit instruction, the primary constraint shifts from technical capability to conceptual clarity. This represents not just a quantitative acceleration of existing processes, but a qualitative shift in the relationship between thought and creation.
2. How will these technologies redefine the nature of expertise and creative identity?
As AI systems embody increasingly 🧠 sophisticated domain knowledge—understanding cinematography, visual composition, narrative continuity—questions arise about the evolving role of human expertise. Rather than simply replacing human capabilities, these technologies seem to be creating new collaborative relationships between human creative vision and machine execution. The person who can effectively direct an AI system may embody a fundamentally different type of expertise than the traditional technical specialist—one focused on intention, evaluation, and refinement rather than manual execution.
3. What becomes possible when we integrate these complementary capabilities?
Perhaps the most exciting potential lies not in any individual technology, but in their integration. When Luma’s generative capabilities meet Twelve Labs’ analytical capabilities, when Nova’s interaction models connect with enterprise knowledge bases, entirely new workflows and possibilities emerge. The complementary nature of these technologies—some focused on understanding existing content, others on generating new content, still others on facilitating natural interaction—suggests a future of integrated systems that amplify human creative and analytical capabilities across domains.
For industry participants across the spectrum, these demonstrations illustrate how AI is fundamentally altering the relationship between conception and execution. Technical barriers that once separated ideation from realization are dissolving, creating new opportunities:
-
For developers: API-first approaches that bridge technical and creative workflows
-
For investors: Clear ROI models through production cost reduction and operational efficiency
-
For creative professionals: Tools that extend capabilities without replacing core expertise
-
For enterprises: Solutions that scale content creation while maintaining brand consistency
-
For entrepreneurs: Accessible platforms that democratize previously specialized capabilities
What emerged most clearly was the bidirectional nature of this evolution—technical innovations influencing creative possibilities, while creative applications drive technological advancement. As Arte Merritt observed in his closing remarks, “We’re not just witnessing incremental improvements to existing processes, but the emergence of entirely new creative paradigms and business models.”
In the words of Martha Graham, whose thoughts on movement seem unexpectedly relevant to this technological moment: “There is a vitality, a life force, an energy, a quickening that is translated through you into action, and because there is only one of you in all time, this expression is unique.” These technologies promise to amplify that uniqueness—not by replacing human creativity, but by removing barriers to its fullest 🌕 expression.

APPENDIX A: FULL SHOWCASE AGENDA
(confirmation pending)
AWS Gen AI Loft – Bedrock Demo Night
Date: April 16, 2025
Location: AWS Gen AI Loft, San Francisco
Host:
- Arte Merritt, AWS Gen AI Strategic Partnerships & Marketing
Featured Demos and Speakers:
1. AWS Bedrock & Nova (AWS)
-
Presenter: Jean Malha, AWS Generative AI Specialist
-
Highlighted Technologies: Nova App: Browser automation SDK utilizing natural language Nova Sonar: Speech-to-speech model for fluid, natural conversational AI
2. Eleven Labs
-
Presenter: Travis Couture, Director of Solutions Engineering, TwelveLabs
-
Highlighted Technologies: Moringa: Unified Embedding Model for advanced multimedia search and retrieval Pegasus: Video-to-Text Model enabling deep contextual video analysis
3. Luma AI
-
Presenter: Jesse Gillette, Head of Business Development and Partnerships @ Luma AI (formerly Spotify, Pandora)
-
Highlighted Technologies: Photon: Foundation model for images enabling creative previsualization Ray: Video Foundation Model excelling in character consistency, motion continuity, and expressive cinematic visualization
4. Postt
-
Presenter: Zahiduli Islam, Founder of Postt and Jutsu
-
Description: AI-powered content creation & social media automation platform designed for streamlined, consistent brand presence for founders and entrepreneurs
5. Tofu
-
Presenter: Hong Lei (sp?), Founder
-
Description: Unified content personalization and automation platform for B2B marketers, featuring intelligent landing-page customization and CRM integration
6. HeyBoss
-
Presenter: Ms. Qu
-
Description: AI-driven platform rapidly generating complete websites and apps from single-sentence prompts, offering fully integrated solutions with minimal user input

AFTERWORD: THE CHOREOGRAPHY OF BECOMING
The demonstrations at AWS Gen AI Loft it seems to me reveal a profound truth: we stand at the convergence of two evolutionary streams. Physical expression—the body’s inherent 🌀 intelligence and vocabulary—and computational intelligence are no longer parallel paths but intertwining forces.
Movement and code share fundamental properties: both operate through pattern, intention, and responsive adaptation. The image recognition capabilities of Twelve Labs mirror how we recognize a gesture’s meaning across contexts. Luma’s fluid 🪷 rendering of motion echoes the body’s innate understanding of physics and weight. Nova’s conversational fluidity approaches the natural exchange of human dialogue.
These symmetries suggest not separate domains but a unified field of expression where the distinctions between physical and digital become increasingly permeable. As these technologies mature, the question shifts from what machines can replicate to what new forms of expression might 🕊️ emerge from this synthesis—new choreographies of possibility that neither human nor machine could discover alone.
In this unfolding reality, we need not fear obsolescence but instead recognize opportunity: the chance to expand the vocabulary of expression beyond traditional constraints. The true potential lies not in replacement but in amplification—technologies that extend our expressive range while preserving the essential 🔆 human quality of creative intention.
The future unfolding before us isn’t about transcending the body but about extending its vocabulary—creating a more nuanced dialogue between physical intelligence and computational capability, each informing and transforming the other in an ongoing 🪶 dance of becoming.
https://bsky.app/profile/schwentker.bsky.social/post/3ln2ib47lkk2r