
Based on NVIDIA GTC 2025 presentation by Raed Al-Tikriti, Chief Product & Technology Officer, Disguise
“It’s one platform. The key aspect is the pre-visualization of our software that allows you to build and pre-sequence a production…at scale.” — Raed Al Tikriti
In the sprawling arena, 70,000 fans erupt as their favorite artist steps into a cascade of light ✨. Behind this spectacle, an invisible technological revolution unfolds. Far from the audience’s view, AI algorithms are rendering the performer in real-time, creating a bridge 🌉 between physical and digital existence that was previously impossible without specialized equipment, extensive camera arrays, and prohibitive costs.
The live events industry has long been caught in a challenging position—trying to deliver increasingly immersive experiences while constrained by technological limitations and budget realities 💸. The fundamental challenge has remained stubbornly persistent for decades: how to accurately preview and plan productions that blend physical performance with digital environments before the costly on-site rehearsal phase.
Most production teams have resorted to two imperfect approaches: either superimposing flat video of performers onto digital previews (masking critical details and creating scaling issues) or relying on experienced operators who mentally “eyeball” 👁️ how performances might integrate with digital elements—a method one industry insider describes as “non-accurate and cannot be easily reviewed later offline.”
But what if there was a third way? What if standard cameras could capture performers with depth information that allows them to be accurately placed within virtual environments? This question has driven Disguise’s latest innovation in volumetric capture technology, potentially changing how productions are conceived, rehearsed, and executed.

Traditional Volumetric Capture 🧤Challenge
Volumetric capture—the technique of creating three-dimensional digital representations of people and objects from camera footage—has traditionally required either extensive camera arrays or specialized equipment 🧰:
-
Neural Radiance Fields (NeRFs) use deep neural networks to create view-dependent radiance but must be retrained for different scenes, making them impractical for dynamic performances
-
Gaussian Splats break images down into point clouds and 3D Gaussians, but require substantial data
-
Photogrammetry uses multiple cameras in precise arrangements, creating logistical challenges
-
LIDAR/Structured Light approaches reduce camera requirements but demand specialized equipment
For productions featuring performers like Beyoncé 🎤 or major events like Eurovision, these limitations have meant either enormous technical investment or creative compromise. The ideal solution would require minimal equipment while delivering maximum flexibility.
As Al-Tikriti explains: “Can we build a Volumetric Capture solution utilizing a sparse camera setup that doesn’t require specialist equipment?”

Depth Estimation🐛 Breakthrough
The breakthrough lies in recent advances in AI-powered depth estimation—algorithms that can analyze a standard 2D video and calculate the relative distance between objects and the camera 🎥. Using open-source algorithms rather than specialized RGBD cameras, Disguise has built a tool that can take footage from a single camera and transform it into 2.5D assets for rendering in their Designer platform.
This approach offers several key advantages:
-
Accessibility: Standard cameras can be used without specialized depth-sensing hardware
-
Simplicity: The capture setup is dramatically streamlined
-
Flexibility: Performance capture can happen in regular rehearsal spaces
-
Integration: Assets can be seamlessly integrated into Disguise’s existing previsualization workflows
The core technology leverages recent advances in monocular depth estimation—a field that has seen remarkable improvements through deep learning. By analyzing visual cues like perspective, occlusion, familiar object sizes, and texture gradients 🌀, these algorithms can infer depth information from standard video with increasing accuracy.

Inside the Technology: How AI Makes 🔍it Possible
The prototype tool Disguise engineers have developed combines several AI approaches:
-
Depth estimation algorithms to calculate relative distances
-
Segmentation algorithms allowing users to select specific areas of interest
-
Processing pipelines that convert this information into usable 2.5D assets
In testing various AI models, the team discovered significant differences in performance:
-
Depth Anything (with both large and small checkpoint sizes) performed well for still imagery
-
Apple’s Depth Pro offered certain advantages but had limitations
-
Video Depth Anything proved superior for motion, solving critical temporal stability issues
The testing process revealed key challenges that needed addressing:
Temporal 🕰 Stability
Early frame-by-frame algorithms produced inconsistent results when processing video, creating jarring visual artifacts as the depth estimation fluctuated between consecutive frames. Video Depth Anything’s approach proved significantly smoother, maintaining consistent depth interpretation across time.
“As we started to run these algorithms through, we started to notice issues with any frame by frame algorithm…there was a temporal issue as it tried to interpolate across the frames,” notes Al-Tikriti.
Spatial 🧭 Calibration
Models returning “metric depth” results showed considerable variation from ground truth measurements, indicating that significant spatial calibration is necessary before rendering results. This calibration ensures that performers appear at the correct scale and position within virtual environments.
Lighting 💡Variations
Perhaps most challenging, the models showed inconsistent performance under variable lighting conditions and when dealing with reflective surfaces. This presents particular challenges for live event environments where lighting is not just variable but an integral part of the creative expression 🎨.
“A final major problem is that these models do not perform well under variable lighting conditions or with reflective surfaces. This is something that should be resolved before the use in production spaces.”

From Prototype to Production🚀
The prototype demonstrates impressive capabilities while highlighting areas for future development. Currently, the system:
-
Takes standard video input
-
Allows user-controlled segmentation to isolate performers
-
Generates depth maps for each frame
-
Creates 2.5D assets that can be imported and manipulated in Disguise Designer
The integration with Disguise’s ecosystem means that producers can place these performer assets into virtual stage mockups 🪄, testing how performances will interact with digital environments, lighting designs, and screen content before expensive on-site rehearsals begin.
This represents a fundamental shift in preproduction workflows. Rather than waiting until technical rehearsals to see how performers interact with digital elements, creative teams can explore these relationships during early planning stages. The Eurovision example highlighted in the presentation shows side-by-side comparisons of the previsualizations and final results, demonstrating remarkable accuracy.
Rendered echo sways codebound 🎭 puppet rehearses stitched by motion’s light

Beyond Preproduction🔮: Future Applications
While the immediate application focuses on preproduction, the potential extends much further:
- 3D Streaming of Live 🌐 Events
A collaboration with the BBC explored using depth estimation to enhance the streaming of live events into metaverse environments. Though early models proved insufficient, newer algorithms could potentially enable real-time volumetric streaming of performances.
“On a recently concluded research project, partners at the BBC investigated using depth estimation to enhance the streaming of live events into a metaverse environment.”
- VR Content 🧬 Creation
Disguise recently introduced features allowing VR content creation on LED stages. Volumetric capture could significantly enhance this workflow, enabling the full transfer of both environments and performers into virtual worlds.
- Multi-Camera Synthesis🎥
The logical next step involves multi-camera synthesis—combining depth information from different viewpoints to create full volumetric assets rather than 2.5D representations. This could potentially work with non-uniform camera arrangements, overcoming key limitations of current approaches.
- Real-Time Proces⚡sing
Current processing times remain a barrier to live applications. As the presenter notes: “The current algorithm is non-realtime. It takes seconds to process, but we need it to go significantly faster.” Achieving real-time or near-real-time processing would unlock live applications where performers could be volumetrically captured and streamed instantly.
- 🧊 Physical-Based Rendering
Looking further ahead, integration with NVIDIA’s DiffusionRenderer could enable AI-powered physical-based rendering that accurately simulates material properties of captured objects, creating even more realistic virtual representations.
“A goal would be to use the diffuser in the future to give us the ability to have that action interact properly with the objects being captured.”
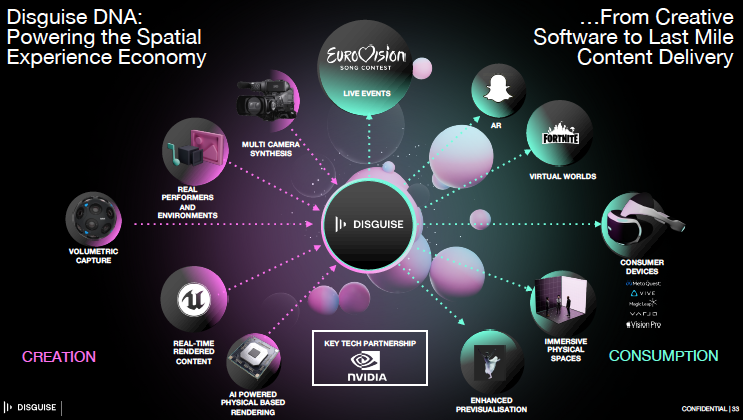
The Larger 🌍 Implications
This technology sits at a critical junction between content creation and consumption in what Disguise terms “the spatial experience economy.” Their vision positions volumetric capture as part of a broader ecosystem connecting real performers and environments with multiple consumption channels:
-
Live events
-
Virtual worlds
-
Augmented reality
-
Consumer devices
-
Immersive physical spaces
The significance extends beyond technical achievement. By reducing the expertise, equipment, and cost barriers to volumetric capture, this approach could democratize immersive content creation in ways previously unimaginable 🌱. Productions with modest budgets could leverage techniques once reserved for the most expensive shows.
Reflections🪞 & Implications
As we consider the implications of this technology, several questions emerge:
What does it mean for the creative process when directors can accurately visualize performer interactions with digital environments before stepping into a venue? How might this reshape the economics of production when creative decisions can be finalized before expensive technical rehearsals begin?
“The key aspect is the pre-visualization of our software that allows you to build and pre-sequence a production,” Al-Tikriti notes. But beyond efficiency, there’s a creative liberation in this approach—allowing designers to explore possibilities that would be too risky or expensive to attempt without such previsualization.
More philosophically, as the boundaries between physical and digital performance continue to blur, what new forms of artistic expression might emerge? When performers can be captured, manipulated, and placed into any conceivable digital environment, how might this change our understanding of live performance itself?
As one industry observer noted upon seeing the technology, “We are on the edge of something magical.” The quiet revolution happening behind the production curtain 🎭 may soon transform what audiences experience in front of it.
All quotes & technical details sourced from Raed Al-Tikriti’s NVIDIA GTC 2025 presentation on using AI tools to digitize performers in live events
