
Based on Ersin Yumer’s presentation at NVIDIA GTC 2025
In the rapidly evolving landscape of generative AI, a quiet revolution is taking place at Adobe—one that may redefine how we think about scaling 🚀 foundation models for creative applications. As generative AI continues its explosive growth across industries, Adobe’s approach to training video foundation models reveals crucial 💡 insights about the future direction of commercial AI development.
“These are moving super fast,” noted Ersin Yumer, Senior Director of Adobe’s AI/ML Platform and Data, during his recent presentation at NVIDIA GTC 2025. “When we started about two years ago at Adobe launching Firefly image 1… it kind of feels like a century. I use it in 10 years ⏱️ so.”
This accelerated timeline isn’t hyperbole—it’s a reflection of the breakneck pace at which foundation models are evolving. Yet amid this rush, Adobe has charted a distinctly different path from its competitors, one that prioritizes commercial viability, quality, and ethical 🧭 considerations over sheer scale. This approach offers critical lessons for business leaders and technologists alike as generative AI matures into a fundamental business technology.
Beyond the Scale Obsession: Adobe’s Balanced Approach
The conventional wisdom in AI development has long been “bigger is better.” As OpenAI, Google, and others engage in an arms race to build ever-larger models trained on increasingly 🏗️ massive datasets, Adobe has pursued a more nuanced strategy.
“I know everybody says bigger, the better,” Yumer acknowledged, “but I think we have been starting to see some smaller models and different architectures, also bringing quite a lot of power without necessarily just scaling at the greedy 🧠 side.”
This statement reflects a profound shift in thinking about AI model development. While internet-scale training has dominated headlines, Adobe’s focus on quality over quantity offers a compelling alternative vision for businesses seeking to integrate 🧩 AI into their products and services.

The Commercial Data Difference
Perhaps the most striking aspect of Adobe’s approach is its data strategy. Unlike many competitors who scrape the internet indiscriminately for training data, Adobe relies exclusively on licensed 📚 content.
“One of the most important things that we have made a decision at Adobe from the beginning of our GenAI journey has been using sourced data,” Yumer emphasized. “We use data to train our models that are only licensed to us. And they are trainable because we have the rights ⚖️ to train all those models.”
This strategy yields three critical advantages:
-
Commercial safety guarantees for customers
-
Higher quality training data from professional sources
-
Ethical clarity regarding rights and permissions
Adobe primarily leverages content from Adobe Stock, where creators explicitly grant training rights. While this results in a dataset “a lot smaller than internet scale,” Adobe has found that “higher quality comes before 💎 scale when using your data.”
This approach represents a fascinating strategic wager: that curated, high-quality, licensed data will ultimately produce better commercial outcomes than the “more is more” philosophy that dominates much of AI 🏭 development.

Technical Innovations: Scaling Through Efficiency
Despite working with a more constrained dataset, Adobe has developed sophisticated technical approaches to maximize efficiency and quality. Their progressive training methodology reflects deep insights about learning 🔍 dynamics in multimodal systems.
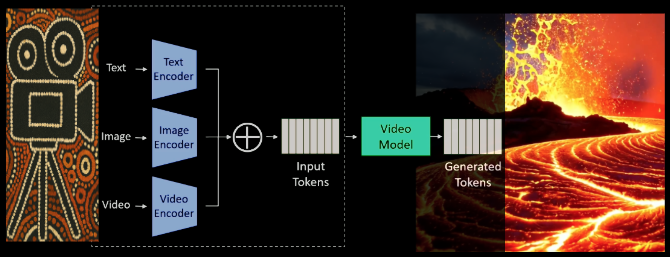
Progressive Resolution Training: From Images to High-Res Video
Adobe’s training approach begins with images before gradually introducing video at increasing resolutions. Yumer explains the logic: “Start with images first, and if you’re just given computational efficiency, we just get better utilization of the available 🧮 data.”
This progression enables more stable training by allowing the model to:
-
Learn spatial relationships from static images
-
Develop basic motion understanding from low-resolution video
-
Refine detailed dynamics with medium-resolution video
-
Master complex visual elements with high-resolution video
“Once you start adding larger and larger resolution video training data, you start actually transferring that spatial knowledge… and then you learn the lower-speed to slower-speed 🌊 dynamics,” Yumer explained.
This methodical approach reflects a sophisticated understanding of how visual foundation models learn—starting with broad patterns before refining to increasingly complex 🧵 dynamics.
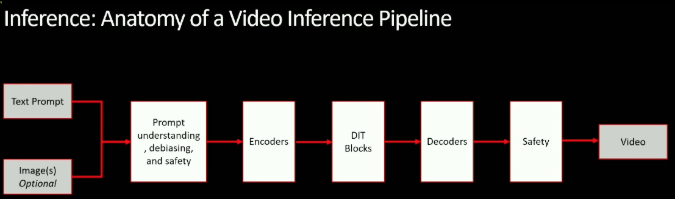
Optimization Innovations: The Inference Efficiency Revolution
Perhaps the most impressive technical achievement lies in Adobe’s optimization of inference—the process of actually generating video once the model is trained.
“Just pure PyTorch BF16 inference with our latest model would be taking one step only in 3 seconds. If you think about the diffusion steps, right? You’ll end up with over 2 minutes to generate just one ⏳ video,” Yumer noted.
This presented both a user experience problem and a cost challenge. Adobe’s solution involved a multi-stage optimization approach:
-
Implementing TensorRT runtime with optimized kernels (30x improvement)
-
Developing mixed precision quantization techniques (70x total improvement)
These optimizations transformed an impractically slow generation process into one that could support commercial applications at scale. The business implications are profound: without these efficiency gains, the economics of running foundation models for video generation would likely be prohibitive for most commercial 💼 applications.
Distributed Attention and Stochastic Data Pendulum
One of the most fascinating technical innovations involves Adobe’s solution to multi-modal training data challenges. When training with different data sources (images, low-res video, high-res video), naïve approaches led to inefficient resource 🔃 utilization.
Adobe developed what Yumer calls a “stochastic pendulum” approach, which maximizes “data source split between the nodes and the GPUs.” This creates deliberate imbalance across processing nodes to fully leverage distributed attention 🧭 mechanisms.
The result is more efficient training and better utilization of limited but high-quality data—a crucial advantage when working with a smaller, commercial dataset rather than internet-scale 📊 data.
Production at Scale: The Kubernetes Auto-Scaler
Moving from training to production required solving an entirely different set of challenges. With multiple models serving different applications across Adobe’s ecosystem, optimizing inference became a complex orchestration 🎻 problem.
“We don’t have one pipeline on our infant side,” Yumer explained, “because everything we were talking about—multiple types of compute, types of logic in your entire pipeline—is made even more complex and complicated if you have multiple 🌐 applications.”
Adobe’s solution was to develop a custom Kubernetes auto-scaler that dynamically optimizes compute resources across applications based on real-time traffic patterns. This system:
-
Monitors demand across different applications
-
Reallocates compute resources to meet changing needs
-
Optimizes cost by shifting resources rather than simply scaling up
This approach allows Adobe to efficiently manage “tens of thousands of GPUs and many different kinds of compute” across applications that experience varying demand levels throughout the day and 📆 year.
Business Implications: The Commercial Viability Equation
For business leaders considering AI investments, Adobe’s approach offers a compelling framework for thinking about commercial viability. Rather than pursuing the largest possible model, Adobe has optimized for what matters in a business 📈 context:
-
Legal clarity and risk mitigation through licensed data
-
Cost efficiency through advanced optimization techniques
-
Quality control through curated professional content
-
Scalable deployment through sophisticated orchestration
This balanced approach has allowed Adobe to integrate generative capabilities across its product ecosystem while avoiding many of the legal and ethical pitfalls that have challenged other AI 🛡️ deployments.

The Future: Beyond Diffusion Models
While Adobe’s current video models rely on diffusion-based approaches, Yumer acknowledged that future developments may take different architectural directions. When asked about auto-regressive models, he 🔮 noted:
“Do we have auto-regressive models that we’re working on? Yes, and the time and the quality that we could get this model to… this particular approach was the one that we were able to get to the point where we were satisfied with the quality and efficiency. So we really wanted to go out, but we’re not stopping here 🚶 for sure.”
This hints at a pragmatic philosophy: deploy what works now while continuing to explore what might work better tomorrow. For business leaders, this balanced approach to innovation—rather than chasing the latest technical trends—offers a sustainable path to incorporating AI into products and 🌱 services.
Key Takeaways for Business Leaders
Adobe’s approach to training video foundation models offers several valuable lessons:
-
Quality over quantity: Curated, high-quality data can outperform raw scale
-
Optimization matters: Technical efficiency can transform economically unviable models into commercially successful ones
-
Legal clarity creates business value: Licensed data provides commercial guarantees that can differentiate AI offerings
-
Balanced innovation: Pragmatic deployment of current technologies while researching future approaches
-
Dynamic resource management: Sophisticated orchestration can significantly improve economics of AI at scale
As the industry continues to evolve, Adobe’s measured approach suggests that the future of commercial AI may not belong to those with the biggest models or the most data, but rather to those who can most effectively balance quality, efficiency, legal clarity, and user ✨ experience.
For business leaders navigating AI implementation decisions, Adobe’s journey offers a compelling alternative to the “scale at all costs” narrative that has dominated much AI discourse. The question is no longer just “how big can we go?” but “what’s the most efficient path to delivering real 💫 value?”
In the long run, this balanced approach may prove more sustainable and commercially viable than the brute-force scaling that has characterized much of AI’s recent development. As foundation models move from research curiosities to commercial products, the lessons from Adobe’s journey will become increasingly relevant across 🌍 industries.

Q&A Highlights ✳️
The presentation concluded with an insightful Q&A session that further illuminated Adobe’s unique 🧬 approach:
On Progressive Training Strategy: An audience member questioned the multi-layer training strategy: “You have a multi-layer training stage where first you train a model using only images 🖼️. And then you do low-res video, medium and high-res. Would that mean that your pre-training is paid cheap?”
Yumer clarified that these progressive steps are actually part of the pre-training process itself, with the image-only phase representing “maybe one tenth of pre-training only.” The specialization phase that follows high-resolution 🎥 training is comparatively lightweight🪶, “probably like one, two, three percent” of the total compute.
On Data Strategy and Scale: When asked about Adobe’s training data, Yumer reinforced their distinctive approach: “We use a very different data strategy compared to most others in the industry or in open source. We don’t use internet 🌐 scale data.”
Instead, Adobe primarily leverages content from Adobe Stock “where creators bring their own work” and have explicitly “given Adobe the right for training.” While more constrained than internet-scale approaches, this still represents “hundreds of millions 📦 of at least initial role set of assets.”
On Future Optimization Potential: A particularly forward-looking question addressed the potential for even more aggressive quantization: “How far are we from going to FP4 and how much will the GPUs really help you for these kinds of models?”
Yumer expressed optimism 🌠 about further advances, suggesting “another 30 to 70 percent would be added from an efficiency perspective” while acknowledging the challenges 🎲 in maintaining visual quality at such extreme quantization levels.
This article is based on Ersin Yumer’s presentation at NVIDIA GTC 2025, where he discussed Adobe’s approach to training video foundation models at scale.