
2024 is officially the year AI agents moved from experimental concepts to production deployment. This analysis distills critical insights from LangChain’s CEO to provide a clear understanding of this revolution and its business implications for forward-thinking professionals.
In Silicon Valley, amidst the relentless hype cycles and promises of AI transformation, a quiet revolution has been taking place. While generative AI grabbed headlines through 2023, a more subtle but arguably more significant shift was occurring: AI agents—autonomous systems that can plan, reason, and execute complex tasks—began moving from research labs into production environments at scale.
“2024 absolutely has seen agents come about,” says Harrison Chase, Co-Founder and CEO of LangChain, the developer platform powering much of this agent infrastructure. “It’s not easy to build agents, but it is possible. And teams are figuring out and using tools and techniques to get them into production.”
As enterprises race to implement generative AI solutions, the most sophisticated organizations have already moved to the next phase: deploying autonomous agent systems that fundamentally transform how work gets done. According to Chase, who has spent months speaking with dozens of executives leading these implementations, a consistent pattern has emerged: organizations that understand the strategic implications of agent systems are gaining significant operational advantages that extend far beyond basic AI applications.
This deep dive explores the current reality of enterprise AI agents in 2024, the infrastructure supporting them, and what executives need to know to navigate this rapidly evolving landscape.
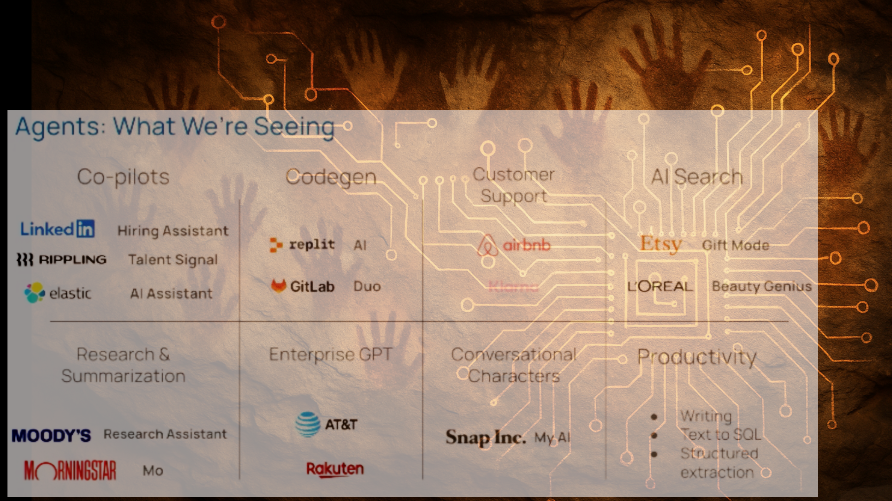
The State of AI Agents in 2024:⏳
Production-Ready but Not Plug-&-Play ⚙️
AI agents represent a fundamental shift from the more passive, prompt-response AI interactions we’ve grown accustomed to. Unlike simple chatbots or text-generation systems, agents actively pursue goals through planning, using tools, and adapting to feedback—much closer to how human knowledge workers approach complex tasks.
Chase describes the simplest agent algorithm as “running a for-loop or a while-loop where you’re calling an LLM, asking it to decide what to do next. If it wants to call a tool, you execute that tool, get back an observation, pass it back into the LLM, and continue until the agent decides to finish.”
This deceptively simple framework enables remarkable capabilities when implemented well. Enterprise agents are now routinely handling tasks like:
-
Internal knowledge work 📚💎: Analyzing documents, extracting insights, and generating comprehensive reports
-
Customer support 🛟🔍: Resolving complex support issues by accessing multiple systems and databases
-
Research automation 🧩🔮: Answering complex questions by searching across internal knowledge bases and the internet
-
Code generation and maintenance ⚙️🦗: Writing, debugging & documenting code across multiple systems
“We’ve seen everything from co-pilots, the first iteration of code gen and customer support, to larger use cases,” notes Chase. “Customer-facing agents, more consumer-facing ones, and AI search, research, and summarization—which is a huge internal use case.”
However, executives should understand that deploying successful agent systems isn’t as simple as purchasing off-the-shelf solutions. The technology has matured significantly but still requires thoughtful implementation and infrastructure.
The Infrastructure Powering Agent Deployment🏗️
For executives, understanding the infrastructure behind agent systems is crucial not for technical micromanagement, but because it directly impacts deployment costs, security considerations, and integration capabilities.
The fundamental infrastructure stack enabling enterprise AI agents consists of:
-
Foundation models 🧠🚀🌐: The underlying AI engines from providers like OpenAI, Anthropic, Google, and increasingly, open-source alternatives
-
Orchestration frameworks 🔄: Systems like LangChain that connect models with tools, data sources, and business logic
-
Development environments 👩💻⚒️🧪: Specialized IDEs and tooling for building and testing agents
-
Deployment infrastructure 🏗️☁️🔐: Platforms that enable secure, scalable deployment
-
Evaluation systems 📊🔍⚖️: Tools to monitor performance and ensure reliability
Chase emphasizes that “a lot of the systems that we see out there already are multi-agent systems,” even if they’re all built by the same team and running in the same process. The real frontier is enabling these systems to operate in distributed environments, communicating across organizational boundaries.
“These can be multiple agents that you built running separately, other internal agents that other teams built, or external agents,” he explains. “How do you call those agents from your internal agents? How do they collaborate? We see a lot of people thinking about this.”

The Three Critical Challenges Facing Enterprise Agents🚧
Despite significant progress, three primary challenges remain for enterprise agent implementation:
1. Multi-Agent Systems and Deployment Infrastructure 🔄
The most forward-looking organizations are now thinking beyond single agents to multi-agent systems, where specialized agents collaborate to accomplish complex tasks. This mirrors how human teams operate, with specialists handling different aspects of a project.
“One of the things that we’re thinking about to tackle this is LangGraph Platform,” Chase says. “We built a lot of the infrastructure for running these applications. We’re also building tools for accelerating development.”
The deployment challenges are particularly acute for enterprises:
-
Data sensitivity🔒🏢: Enterprise data requires secure, often on-premises deployment
-
Long-running processes ⏱️🔄: Unlike simple chatbots, agents often run lengthy operations that may span hours
-
Horizontal scalability 📈: Enterprise systems need to support thousands of concurrent agent instances
-
System reliability 🛡️🔧: Business-critical functions require robust failure handling
“Agents are fired off in one action, and they might run for a long time. Spreadsheet teachers fire a thousand agents from one action,” Chase explains. “You need to be able to scale horizontally and scale up. They’re flaky in two ways: one, they’re flaky in the general way—these are API calls, availability providers go down occasionally—but they’re also flaky in ways that are specific to agents.”
2. Memory Systems: A Missing Piece 🧠
Perhaps no aspect of agent systems remains as unsolved as memory—how agents recall past interactions, learn user preferences, and maintain context over time.
“Memory is still very researchy in my mind,” Chase acknowledges. “I would not say it’s a solved problem.”
Chase identifies three types of memory systems mirroring human memory:
-
Semantic memory 📚🧠: Facts and knowledge (equivalent to retrieval from documents)
-
Episodic memory 📅👤: Experiences and interactions with users
-
Procedural memory 📋⚙️: Instructions and processes (the system prompt)
The challenge lies in extracting meaningful information from interactions and storing it appropriately. Chase points out a key insight: “A key part of memory is using an LLM to reflect on user interactions, and those reflections are what’s stored in the vector database or key-value store. You sometimes don’t even need to do retrieval.”
This reflection process can happen either in the conversation flow itself or as a background process that runs asynchronously. Each approach offers tradeoffs:
-
In-conversation reflection 💬✨: Provides immediate updates & transparency
-
Background processing ⏱️🔄: Reduces latency but delays memory updates
For executives, the practical takeaway is that memory systems provide a significant competitive advantage in agent applications but require domain-specific implementation. Generic solutions don’t yet exist.
“Right now, we see that you need this modular control that you can get through a language building framework rather than just a high-level API,” Chase explains. “As a developer, you probably want to have a pretty low-level control. What a research agent might remember versus what Florida’s customer support agents might remember—they might want to extract different facts in different ways.”
3. Reliability & Planning 🧭 🎲🎯
For agents to be trustworthy in enterprise environments, they must reliably accomplish their stated goals—a challenge given the inherent unpredictability of large language models.
Chase identifies two main sources of reliability issues:
-
Communication problems 📣: Not specifying the task correctly to the LLM
-
Model limitations 🧩: The LLM simply not being smart enough for the task
“There’s no silver bullet, but I think we have a good grip on what the right tools are to approach this,” he says.
The approach to improving reliability involves several components:
-
Flow engineering 🔄: Creating application-specific workflows with explicit planning and reflection steps
-
Reasoning models 🧠: Using specialized models like OpenAI’s, DeepSeq’s, and Google’s for complex planning
-
Evaluation 📊: Building custom datasets and metrics for your specific application
-
In-the-loop checks 🔍: Catching mistakes before they reach users
“One of the big issues with agents is when you tell them to do something, they might not actually do it reliably,” Chase explains. “Part of the issue is that they’re okay at calling a single tool, but when you ask them to do multiple tasks over longer time horizons, their performance starts to deteriorate.”
The solution increasingly involves “flow engineering,” where developers create domain-specific workflows rather than relying on general off-the-shelf architectures. This often includes explicit planning steps where the agent considers possible approaches before acting.
“There’s not really any general, off-the-shelf planning agent architectures or reflection agent architectures that we see being incredibly useful,” Chase notes. “Rather, what it is is a lot of custom flow engineering, where developers are learning the domain that they’re building the agent for and baking in specific steps that are application-specific.”

Report Generation Agent: Case Study in Enterprise Implementation📊
To illustrate how these components come together in practice, Chase presented a case study of a report generation agent built in partnership with NVIDIA.
The system tackles a common enterprise need: generating comprehensive research reports on specified topics. The architecture illustrates the multi-agent approach:
-
Prompt refinement agent: Engages users to clarify their needs and define report scope
-
Research agent: Generates queries, executes them against the internet, and gathers information
-
Writing agent: Creates coherent sections based on research
-
Integration agent: Combines sections into a final report
This architecture demonstrates strategic decisions about where to place human involvement. “One of the key considerations about putting the human in the loop is that if you put them everywhere, it’s pretty repetitive and won’t scale much. But if you don’t put them anywhere, the output can be unreliable,” Chase explains.
The human touchpoint is concentrated at the beginning of the process—defining the report structure—which provides maximum leverage over the final output while minimizing repetitive work.

The Enterprise Advantage: Internal Knowledge Workers 💡
While consumer-facing agents grab headlines, the most immediate ROI for enterprises comes from internal knowledge worker applications.
“AI search, research, and summarization is a huge internal use case,” Chase notes.
These internal knowledge worker agents excel at:
-
Document analysis 📄: Extracting insights from unstructured data
-
Research synthesis 🔍: Compiling information from multiple sources
-
Report generation 📊: Creating comprehensive summaries and analysis
-
Knowledge discovery 💎: Finding relevant information across silos
The advantage of these internal applications is that they operate in controlled environments with access to proprietary data, making them both more valuable and more reliable than consumer-facing alternatives.
Customer Support: The Front Line of Agent Deployment 🛎️
Customer support represents another mature application for agent technology. These systems can:
-
Access customer history: Review previous interactions and purchases
-
Query product knowledge bases: Find relevant documentation and solutions
-
Execute actions in CRM systems: Update tickets and customer information
-
Generate personalized responses: Communicate in a manner consistent with brand voice
Chase indicates that customer support was among the earliest production applications for agent technology, likely due to the clear ROI and structured nature of the domain.
The Collaborative AI Ecosystem 🔗
Understanding the emerging ecosystem around AI agents is crucial for executives planning implementation strategies. Rather than a winner-take-all market, a collaborative ecosystem of complementary technologies is emerging.
This ecosystem includes:
-
Model providers 🧠: OpenAI, Anthropic, Google, and open-source alternatives
-
Orchestration frameworks 🔄: LangChain, LlamaIndex, and others
-
Specialized agent platforms 🛠️: Industry-specific solutions
-
Infrastructure providers ☁️: NVIDIA, AWS, Azure, and GCP
Chase emphasized the collaborative nature of the ecosystem in discussions about LangChain’s partnership with NVIDIA and other technology providers. “One of the last things we’re doing around this stuff is thinking a bunch about pre-built architectures,” he notes.
Executive Strategy: Navigating the Agent Revolution 🧭
For executives considering agent implementation, several strategic considerations emerge:
1. Focus on Internal Applications First
Internal knowledge worker applications provide the clearest ROI and operate in controlled environments where reliability issues can be mitigated.
2. Build Domain-Specific Workflows
Successful agent implementations rely on domain-specific workflows rather than generic architectures. Understanding your specific use case is crucial.
3. Plan for Infrastructure Needs
Agent systems require different infrastructure than traditional applications. Consider security, scalability, and reliability requirements early.
4. Emphasize User Experience
User interfaces that provide visibility into agent operations and appropriate control points are crucial for adoption and trust.
5. Start Building Organizational Capability
“Building agents is not like you build an agent and then ship it, and you’re done,” Chase explains. “It’s a continuous, iterative process, and you figure out what people are using the agent for, whether it’s good, whether it’s bad at those tasks, and try to improve.”
Organizations need to develop the capability to iteratively improve agent systems based on user feedback and changing requirements.
The Next Frontier: 2025 and Beyond
While significant challenges remain, the trajectory of agent technology is clear: increasingly autonomous systems that can handle complex knowledge work with minimal human intervention.
Chase suggests that “2025 [may be] the year of agents,” indicating that we’re still early in the adoption curve despite significant progress.
The next frontiers likely include:
-
Truly autonomous agents 🤖: Systems that can operate independently over extended periods
-
Cross-organizational collaboration 🤝: Agents that can securely work with external systems
-
Specialized vertical applications 🏢: Industry-specific agents for healthcare, finance, and legal domains
-
Standardized protocols 📋: Common interfaces for agent communication and collaboration

Conclusion: The Strategic Imperative ⚡
The shift to agent-based AI represents a fundamental change in how enterprises approach knowledge work and automation. Unlike previous waves of AI hype, agent technology is delivering measurable value today while pointing toward even more transformative capabilities in the near future.
For executives, the message is clear: AI agent technology has moved beyond the experimental phase into practical implementation. Organizations that develop the capability to deploy and iterate on agent systems now will gain significant advantages as the technology continues to mature.
The silent revolution of AI agents may lack the splashy headlines of generative AI’s initial emergence, but its impact on enterprise operations may ultimately prove far more profound. As Chase puts it, “Let’s build it together.”
This article distills key insights from Harrison Chase’s keynote presentation “AI Agents in Production: Insights and Future Directions” at NVIDIA GTC 2025.

https://arxiv.org/pdf/2303.11366
Noah Shinn Federico Cassano Edward Berman
Massachusetts Institute of Technology
