
As organizations dive deeper into Generative AI, bridging the gap between experimentation and operational excellence remains a significant challenge. In Part 2 of the Weights & Biases GenAI Master Class: From Prototypes to Production, Charles Frye of Modal took center stage to explore advanced strategies for production-grade LLM inference. With a focus on technical optimizations and evaluation best practices, the session offered actionable insights for both technical teams and executives. 💡🔍
📝 Highlights from Part 2 of the Master Class
🔧 Production-Grade LLM Inference with vLLM
Charles Frye provided an in-depth exploration of vLLM and its role in powering efficient, large-scale inference. Key takeaways included:
-
When to Use (or Avoid) vLLM: Understanding when the trade-offs of vLLM’s high performance make sense for specific workloads.
-
Optimizations for Workload Scalability: Techniques to maximize performance and minimize resource costs, especially in environments with bursty traffic or high variability.
-
Integrating vLLM into Broader Pipelines: Real-world scenarios where vLLM fits seamlessly into existing GenAI workflows.
-
More details: modal.com/docs/examples/vllm_inference
📏 Evaluation: The Foundation of Long-Term Success
“Models are temporary, evaluations are forever.” This principle underscored the critical role of robust evaluation frameworks:
-
Non-Deterministic Outputs: Addressing the inherent variability of Generative AI with comprehensive testing.
-
Key Metrics: Emphasizing responsiveness, accuracy, relevance, and robustness as pillars of effective evaluation.
-
Iterative Improvement: Leveraging Weights & Biases tools to create dynamic feedback loops for continuous refinement.
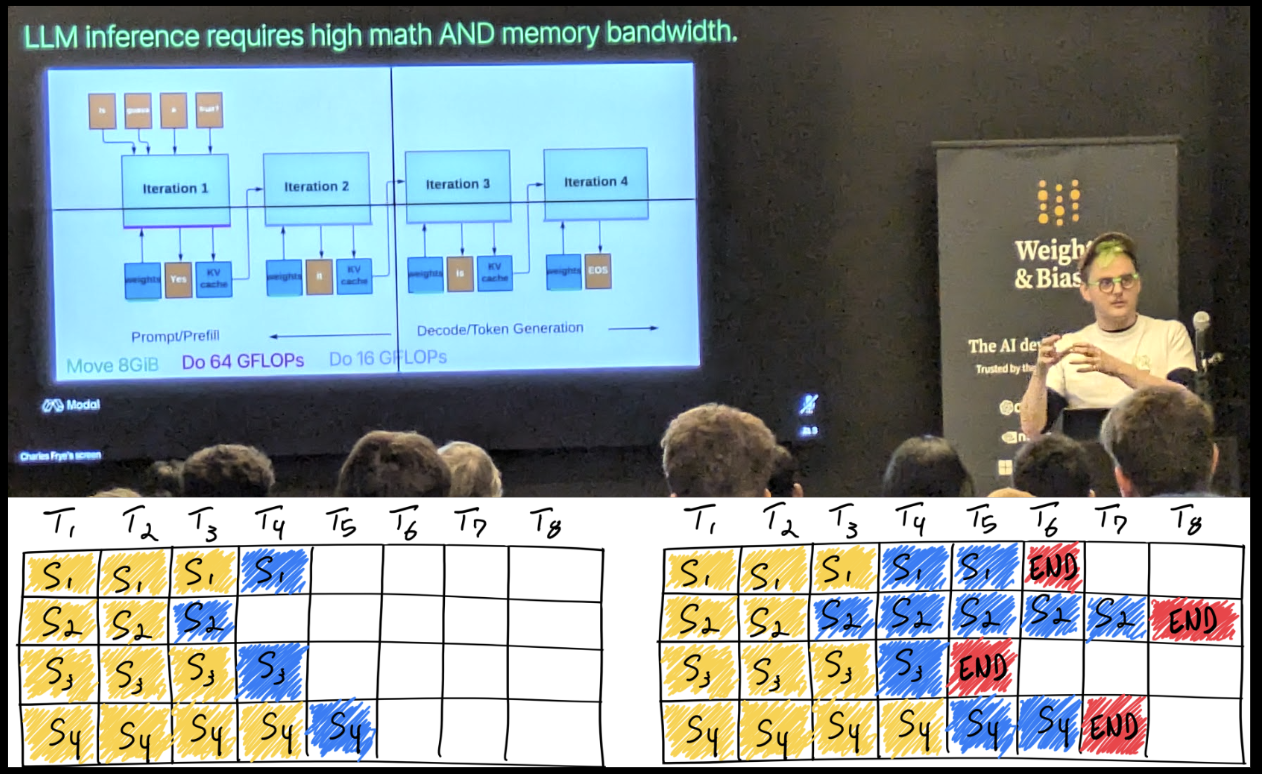
⚡ Performance and Cost Efficiency in LLM Inference
A major focus of the session was balancing cost with performance:
-
Scaling for Bursty Traffic: Strategies for provisioning GPU instances efficiently during peak and off-peak usage.
-
Cold Start Solutions: Insights into Modal’s optimizations for reducing cold start latency in serverless environments.
-
Quantization and Memory Efficiency: How reducing parameter precision (e.g., from float32 to int8) unlocks faster, cost-effective inference.
🤝 Collaboration Across Teams
The Master Class emphasized the need for alignment between technical and executive teams:
-
For Technical Teams: Prioritize experimentation and pipeline optimization to ensure readiness for production.
-
For Executives: Focus on identifying high-impact use cases that align with strategic goals and justify the investment in advanced inference capabilities.
🌐 Looking Ahead: Part 3 of the GenAI Master Class Series
The journey continues with Part 3: “GenAI Master Class: From Prototypes to Production – Build and Deploy a GenAI App End-to-End” 📅 Monday, December 16, 2024 📍 Weights & Biases HQ, SF
This final session will bring everything together, guiding participants through the full lifecycle of building, deploying, and managing a GenAI app. Whether you’re a technical leader or an executive strategist, this hands-on workshop will be invaluable. 🏗️💻
🧩 Call to Action
As GenAI adoption accelerates, the need for thoughtful, scalable strategies has never been greater. Part 2 of the Master Class illuminated a clear path forward: one that blends cutting-edge technical frameworks with rigorous evaluation and alignment across teams.
Let’s innovate responsibly and unlock the boundless potential of Generative AI. 🚀🌍