
YouTube: youtube.com/watch?v=lwMk4gNDCrA
Session Slides: https://pbase.ai/3MhT1Qx
As AI continues to redefine industries, one of the critical challenges for executives and CTOs is managing the balance between performance, cost, and quality in deploying generative AI models. At the recent LLMOps Micro-Summit, Arnav Garg, ML Engineering Leader at Predibase , introduced Turbo LoRA, an innovative fine-tuning method that promises to revolutionize text generation by increasing throughput by 2-3x while maintaining or even enhancing response quality. This article provides an in-depth exploration of how Turbo LoRA addresses the inherent trade-offs of existing fine-tuning methods, setting a new standard for efficient AI deployment. It concludes with key strategic actions tailored for Executives and CTOs.
The Challenge: Speed vs. Quality in LLM Inference
The use of open-source large language models (LLMs) has grown rapidly, offering organizations cost-effective alternatives to proprietary models like GPT-4. However, two significant issues often arise:
-
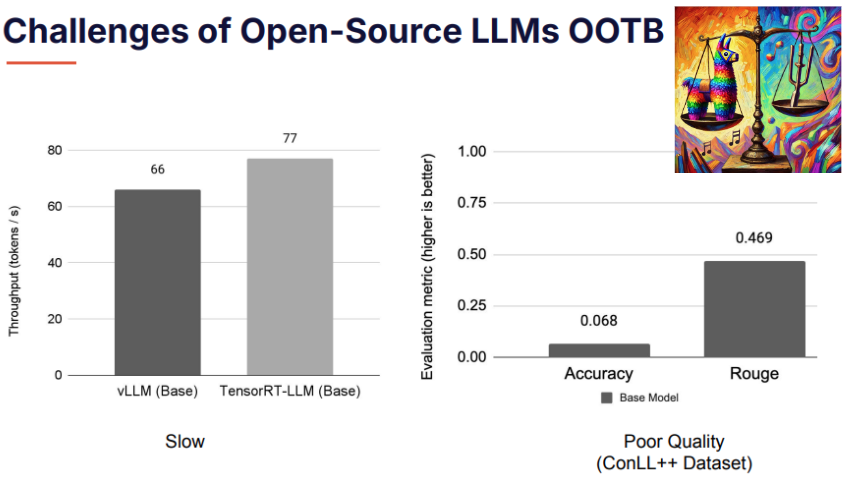
Throughput Limitations: Open-source LLMs generally have lower throughput—about 2-3x slower than GPT-4 or GPT-4 Turbo. This latency can be a dealbreaker for real-time applications like chatbots, summarization tools, or code generation systems that require rapid response times.
-
Quality Variability: While fine-tuning methods like LoRA and QLoRA can significantly enhance the performance of base models, this usually comes at the cost of throughput. Fine-tuning injects new modules into the base model, increasing its computational complexity and slowing down inference speeds.
The industry is thus often faced with a trade-off: optimize for speed or optimize for quality. Arnav posed the key question, “Can we solve both problems without compromise?”
Understanding Throughput Bottlenecks in LLMs
To tackle this problem, it’s crucial to understand why LLMs are inherently slow. Most autoregressive models generate text token-by-token, meaning that after predicting each word, the entire sequence must be fed back into the model to predict the next word. As Arnav explained:
“There’s a linear relationship between the number of tokens generated and the time it takes because it uniformly takes the same amount of time to generate each token. So you’re going to scale your tokens generated by the time, or the time by the number of tokens you generate, and that’s really not a sustainable way to do inference.”
This approach is computationally expensive, especially as the model size increases. So, how can we break this cycle?
Turbo LoRA: Revolutionizing Fine-Tuning for Speed and Quality
The solution, as introduced by Arnav, is Turbo LoRA—an innovative parameter-efficient fine-tuning method that not only improves response quality but also enhances throughput over both standard LoRA and even the base model itself. Turbo LoRA achieves this through a process called speculative decoding, which changes the way autoregressive LLMs generate tokens.

Speculative decoding involves guessing multiple future tokens instead of predicting them one-by-one. By using an assistant model to make these guesses and a primary model to verify them, the system significantly reduces the number of forward passes required through the entire model.
However, this method has its own downsides, as Arnav highlighted:
“The problem with assisted generation is that you actually now have to pay the cost of two models in production. You’ve got the big model, you’ve got the draft model. The second is that the distributions should be the same, which means you need to fine-tune both models on the same data. This is actually quite slow in practice.”
Introducing Medusa and the Birth of Turbo LoRA
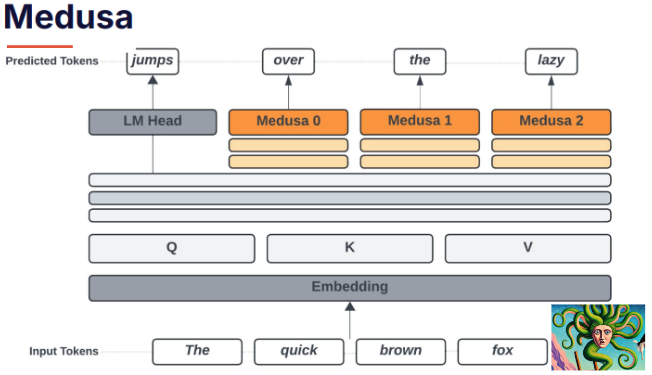
To address these limitations, Predibase looked to a method called Medusa, which adds extra linear layers to the model for faster token generation. Arnav explained:
“What if you could fine-tune for speed? This idea comes from a method called Medusa, where the model’s last hidden state is not only passed through the original language model head but also through a set of linear layers and a copy of the LM head that is fine-tuned.”
While Medusa achieves significant throughput improvements, it requires separate LM heads and additional memory overhead, making it resource-intensive. Predibase saw an opportunity to innovate further by combining the speed benefits of Medusa with the efficiency of LoRA. This led to the development of Turbo LoRA.
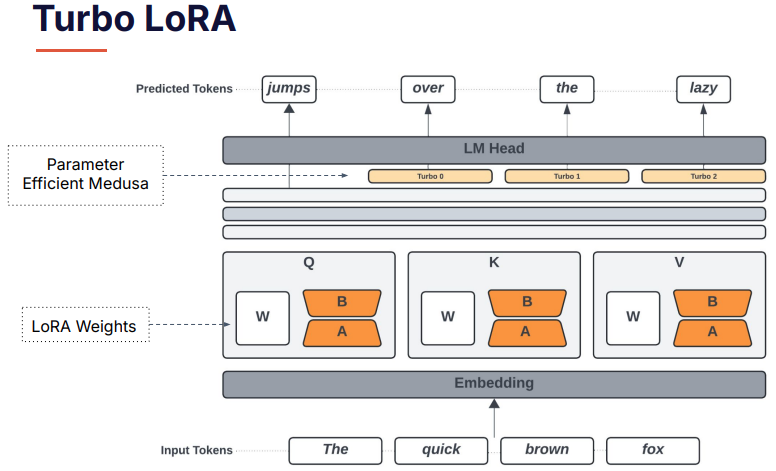
Turbo LoRA integrates LoRA weights directly into the Transformer block’s Q, K, and V projections and fine-tunes them for task-specific quality. At the same time, it removes costly components like separate LM heads and extra MLP layers. This dual adaptation allows for both speed and quality improvements, while also being highly parameter efficient.
Real-World Results with Turbo LoRA
The results of deploying Turbo LoRA have been groundbreaking:
-
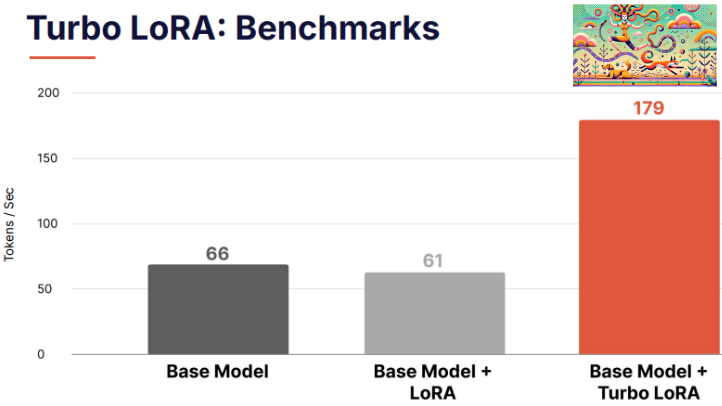
Throughput Gains: Turbo LoRA adapters provided a 3x increase in throughput compared to base models with LoRA, achieving over 200 tokens per second on common datasets like ConLL-2003 (Named Entity Recognition) and MagicCoder (Code).
-
Quality Improvement: Surprisingly, Turbo LoRA not only maintained quality but improved it. On the ConLL-2003 dataset, accuracy increased from 92% to 97%, while the MagicCoder ROUGE score jumped from 0.45 to 0.517.
-
Hardware Agnostic: The method works seamlessly across various GPU types, achieving consistent 2-3x throughput improvements.
Key Audience Questions and Insights
During the presentation, the audience raised several thought-provoking questions:
-
Question from Audience: “How does Turbo LoRA manage to maintain both quality and speed without needing extensive prompt engineering?”
-
Question from Audience: “Is there a specific hardware configuration needed to implement Turbo LoRA in a production environment?”
Strategic Actions for Executives and CTOs
For global executives and CTOs looking to leverage AI for operational efficiency and cost management, Turbo LoRA presents an exciting opportunity. Consider the following strategic actions:
-
Evaluate Your AI Workflows: Assess your current LLM deployments. Identify applications where latency and cost are major concerns, and where fine-tuned models could provide significant benefits.
-
Adopt Parameter-Efficient Fine-Tuning Techniques: Explore Turbo LoRA for specific use cases that require high throughput and quality. The single-line integration capability allows for rapid deployment without significant infrastructure changes.
-
Invest in Flexible Hardware Setups: Ensure your hardware infrastructure supports diverse GPU types to maximize the benefits of parameter-efficient models like Turbo LoRA. Hardware flexibility will enable you to experiment and scale quickly.
-
Leverage Open Source for Customization: Turbo LoRA’s compatibility with over 100 open-source models allows for broad customization. Invest in building a team that can harness these models for tailored business solutions.
-
Monitor and Iterate: Regularly review model performance, especially in production environments. Utilize platforms that support easy versioning, comparison, and iteration of different model types and configurations.
Conclusion
The introduction of Turbo LoRA marks a new era in AI model inference, where both speed and quality can be optimized without trade-offs. For organizations seeking to maintain a competitive edge in AI-driven innovation, adopting such advanced fine-tuning methods will be crucial. By balancing throughput, cost, and accuracy, Turbo LoRA paves the way for more efficient and scalable AI applications across industries. Stay tuned for more updates in the GenAI Architecture Series as we dive deeper into the evolving AI landscape. Next up: “Fine-Tuning SLMs for Enterprise-Grade Evaluation and Observability.”