
LLMOPs Micro-Summit, San Francisco
youtube.com/watch?v=IPDqbfZT1qg&t=1s
As the demand for more efficient, accurate, and cost-effective background checks grows, the ability to transform messy, unstructured text data into meaningful, actionable insights becomes increasingly critical. At the recent LLMOps Micro-Summit, Vlad Bukhin, Staff ML Engineer at Checkr, shared his experience of leveraging fine-tuned language models (LLMs) to automate part of the background check process—specifically, the complex task of categorizing text data into 230 distinct categories. His journey from using OpenAI models and retrieval-augmented generation (RAG) to achieving high accuracy with fine-tuned small models on the Predibase platform offers valuable lessons for global executives and CTOs.
The Problem Space and Challenges
Checkr, Inc. Checkr runs about 1.5 million background checks each month. While most of these checks are straightforward, the remaining 2% are highly complex and require advanced solutions to ensure accuracy. The challenge is to automate the adjudication process—determining whether a candidate passes or fails based on the information in their background check—without excessive manual review or asynchronous processing that could delay decisions. This requires categorizing charge information into 230 specific categories using a synchronous request architecture that can handle fluctuating traffic and request sizes.
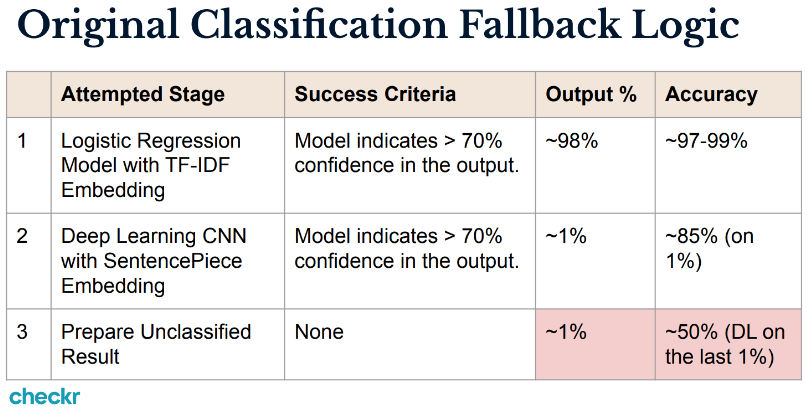
To manage this complexity, Checkr initially relied on a combination of logistic regression with TF-IDF embeddings and deep learning models with SentencePiece embeddings. The logistic regression model handled 98% of cases with 97-99% accuracy, while the deep learning model managed 1% of cases with about 85% accuracy. However, the remaining 1% was unclassified, requiring manual review with only 50% accuracy. This resulted in significant customer frustration and highlighted the need for a more advanced solution.
The Journey to LLM-Based Solutions
Vlad began exploring LLM-based solutions to improve accuracy for the complex 2% of cases. His initial approach was to use large, expert LLMs like GPT-4, which provided decent results but came with high costs and latency. The challenge was to find a solution that would deliver high accuracy, reduce costs, and maintain reasonable inference times.
Design Patterns Tested
During the experimentation phase, Vlad tested several design patterns to find the most effective approach:
-
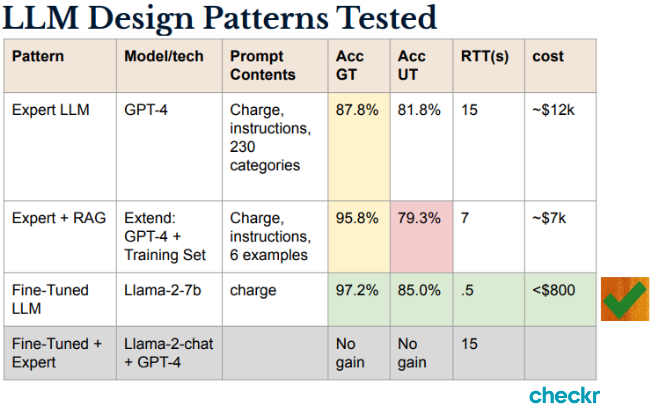
Expert LLM (GPT-4): This approach involved using GPT-4 with a straightforward prompt containing charge instructions and the 230 categories. It achieved an accuracy of 87.8% for general charges and 81.8% for more difficult cases. However, it had a high round-trip time (RTT) of 15 seconds and a substantial monthly cost of about $12,000.
-
Expert LLM + RAG (Retrieval-Augmented Generation): This method extended the Expert LLM approach by incorporating retrieval-augmented generation, using GPT-4 combined with examples from the training set to improve results. While it improved general accuracy to 95.8%, it actually lowered accuracy on the more challenging unclassified cases to 79.3% due to misalignment between retrieved examples and the nuances of the unclassified data.
-
Fine-Tuned LLM (LLaMA 2-7b): Vlad then tested a fine-tuned model, specifically LLaMA 2-7b, tailored to the task of charge classification. The results were impressive, achieving 97.2% accuracy for general cases and 85.0% for difficult cases. The response time dropped to just 0.5 seconds, and the cost was significantly reduced to less than $800 per month.
-
Fine-Tuned LLM + Expert LLMs: In this setup, the fine-tuned model worked in conjunction with an Expert LLM (GPT-4) to validate uncertain predictions. However, this combination did not yield additional gains in accuracy compared to using the fine-tuned LLM alone, which demonstrated that a well-tuned small model could perform effectively without supplementary validation from a larger model.
Optimizing the Fine-Tuning Process
Fine-tuning small models proved to be a turning point in Checkr’s journey towards streamlined, scalable, and cost-effective background checks. The key was to select the right models and hyperparameters to achieve optimal results. Predibase’s platform enabled Vlad to test several mainstream open-source models (such as LLaMA 7B, LLaMA 13B, and the Mistral family) and discard those that showed a lack of convergence or high loss early in the process. Additionally, Predibase’s transparent loss graphs and auto-stopping parameters helped fine-tune the process further.

The fine-tuning optimization process revealed some critical insights:
-
System prompts are less sensitive when a large amount of data is available, meaning that extensive prompt engineering was unnecessary.
-
Implementing LLM inference confidence scores, by adjusting temperature and top-K settings, provided a more accurate distribution of confidence levels.
-
There was no significant change in accuracy when comparing full fine-tuning versus LoRA (Low-Rank Adaptation) fine-tuning, indicating that LoRA can be a more resource-efficient approach.
Deploying the Fine-Tuned Solution on Predibase
With the optimized fine-tuned model ready, Vlad deployed it on the Predibase platform. Using a LLaMA 3-8B instruct adapter on a half A100 GPU, the model delivered consistent, reliable results in production. The fine-tuned model achieved an accuracy of around 90% on the last 2% of complex data, significantly reducing manual review times and improving customer satisfaction.
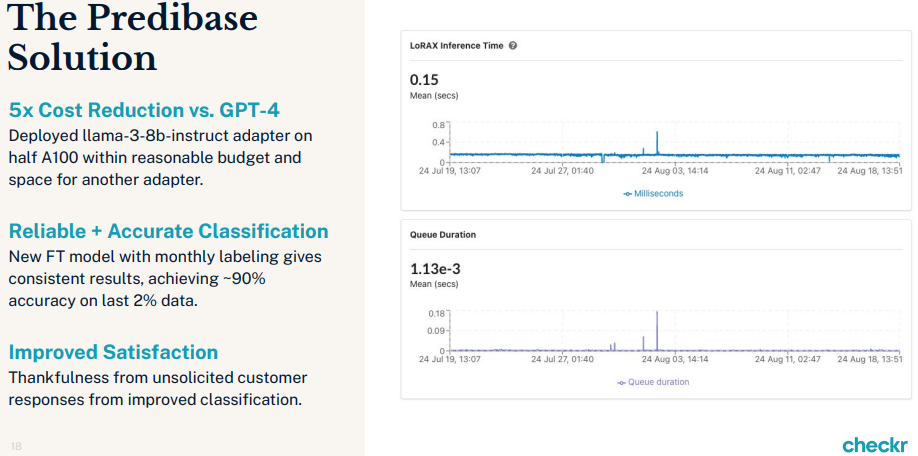
Deploying the model on Predibase led to a 5x cost reduction compared to using large models like GPT-4, without sacrificing accuracy or performance. Moreover, the platform’s flexibility allowed for additional adapters to be added for further solutions, demonstrating scalability and cost-effectiveness.
Key Takeaways for Executives and CTOs
Vlad’s experience at Checkr demonstrates several critical lessons for executives and CTOs looking to leverage AI to streamline complex processes:
-
Prioritize Data Quality: Developing reliable training and evaluation sets is crucial for achieving high model accuracy. Invest time in refining datasets to ensure they are representative and comprehensive.
-
Experiment with Different Design Patterns: Don’t rely solely on one approach. Testing various LLM configurations—like Expert LLMs, Expert LLM + RAG, and Fine-Tuned LLMs—can reveal the most cost-effective and efficient solutions for your specific needs.
-
Fine-Tuning is a Game-Changer: Fine-tuning small models can achieve comparable or even superior performance to large models at a fraction of the cost and latency. Utilizing platforms like Predibase can streamline this process by providing valuable tools for optimization and deployment.
-
Adopt Efficient Production Strategies: The choice of deployment platform and infrastructure significantly impacts the scalability and cost-effectiveness of AI solutions. Predibase’s robust environment for fine-tuning and deploying LLMs proved instrumental in Checkr’s success.
Conclusion
Checkr’s journey to streamline background checks with fine-tuned LLMs highlights the potential of small models in delivering high performance and cost savings. For organizations seeking to enhance their AI capabilities, adopting a similar approach of experimentation, optimization, and efficient deployment can lead to significant operational improvements and customer satisfaction.
Stay tuned for the next post: Next Gen LLM Inference: Blazing Fast + Cost-Effective. We’ll explore Turbo LoRA, Predibase’s latest innovation that boosts text generation speed by 2-3x while maintaining high-quality, task-specific responses.
